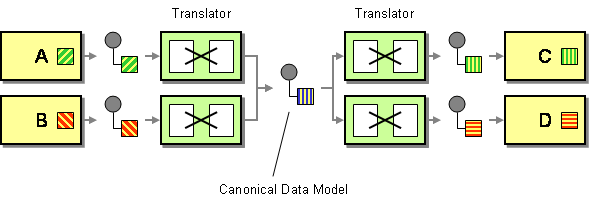
en kanonisk datamodell er definert i Enterprise Integration Patterns som løsningen for å minimere avhengigheter ved integrering av programmer som bruker forskjellige dataformater. Med andre ord, en komponent (et program eller en tjeneste) skal kommunisere med en annen komponent gjennom et dataformat som ville være uavhengig av begge komponentdataformatene.
To ting å markere her. Først definerte jeg en komponent som enten et program eller en tjeneste fordi slike modeller er / ble brukt i sammenheng med applikasjonsintegrasjon og tjenesteorientering. For det andre snakker vi her om et konsept som bare skal brukes som transportdataformat. Du bør ikke bruke et kanonisk dataformat som den interne strukturen i datalageret ditt.
Teoretisk er fordelene ganske åpenbare. Et kanonisk dataformat reduserer koblingen mellom applikasjoner, reduserer antall oversettelser som skal utvikles for å integrere et sett med komponenter, etc. Ganske interessant rett? En enkelt datamodell er forståelig av HELE IT-landskapet og et sett med mennesker(utviklere, systemanalytikere, forretningsinteressenter, etc.) hvem kan dele samme visjon om et gitt konsept.
for praktiske formål er implementering av slike modeller sjelden effektiv skjønt.
en person er ikke det samme konseptet for markedsavdelingen i et forsikringsselskap. Et fly for et flytrafikkstyringssystem har en annen betydning avhengig av om det ble fylt av en pilot eller om det er et pågående fly på toppen av luftrommet ditt. EN PLM-del har en helt annen representasjon avhengig av om den nettopp er designet eller om den må vedlikeholdes av et supportteam.
i de fleste sammenhenger resulterer design av en kanonisk datamodell i en stor datamodell med et komplett sett med valgfrie attributter og svært få obligatoriske (som identifikatorene). Selv om det først og fremst var designet for å lette komponentintegrasjonen, vil du bare komplisere det. I mellomtiden vil modellen din skape mye frustrasjon blant brukerne på grunn av sin iboende kompleksitet (når det gjelder utnyttelse og ledelse). Videre, når det gjelder koblingsproblemet, skifter du bare det et annet sted. I stedet for å være koblet til ett komponentdataformat, blir du tett koblet til et felles dataformat som vil bli brukt av HELE IT-landskapet og underlagt svært hyppige endringer.
I et nøtteskall, i de fleste sammenhenger, bør en kanonisk datamodell betraktes som et anti-mønster. Hva er det andre alternativet enn å vurdere at du fortsatt vil minimere avhengighetene mellom to komponenter som utveksler data?
Domain Driven Design (Ddd) anbefaler å innføre begrepet avgrenset kontekst. En avgrenset kontekst er rett og slett en eksplisitt kontekst der en modell gjelder med klare grenser med andre avgrensede sammenhenger. Avhengig av organisasjonen kan en begrenset kontekst referere til et funksjonelt domene der et objekt brukes, det kan referere til objektstaten selv, etc.
i så fall vil den kanoniske datamodellen som sådan ganske enkelt være den gule delen i følgende diagram:
skjæringspunktet Mellom a, B og C representerer settet med attributter som må være der uavhengig av konteksten(i utgangspunktet de obligatoriske attributtene til den forrige store CDM). Denne delen skal fortsatt være nøye utformet på grunn av sin sentrale rolle. Det er viktig å være pragmatisk. Hvis det i din sammenheng ikke er fornuftig å ha en slik felles modell, bør du bare kaste den bort.
det som også er viktig er et skjæringspunkt mellom to sammenhenger (A Og B, B Og C, C og A). Hvordan kartlegge en objektrepresentasjon fra en kontekst til en annen? Hva er de eksplisitte attributter som skal deles på tvers av to sammenhenger? Hva er de vanlige forretningsbegrensningene mellom to sammenhenger? Disse spørsmålene skal fortsatt besvares av et tverrgående team, men fra et forretningsperspektiv er det fornuftig å heve dem. Det var ikke alltid tilfelle med en ENKELT CDM delt på tvers av potensielt motsatte sammenhenger.
når det Gjelder de delene som ikke deles med andre sammenhenger (i hvitt), bør det Likevel ikke være en del av en bedriftsdatamodell. Du må være pragmatisk. For eksempel, hvis et delsett er spesifikt for et gitt domene, bør det være opp til domeneekspertene å modellere det selv.
En viktig utfordring er imidlertid å identifisere de avgrensede sammenhenger, og Det kan være verdt å minne Om Conways lov:
enhver organisasjon som designer et system vil uunngåelig produsere et design hvis struktur er en kopi av organisasjonens kommunikasjonsstruktur.
de avgrensede kontekstene skal ikke nødvendigvis tilordnes den aktuelle organisasjonen. For eksempel kan en begrenset kontekst omfatte flere avdelinger. Bryte organisatoriske siloer bør fortsatt være et mål for de fleste selskaper.
i TILLEGG introduserer DDD konseptet Anti-Corruption Layer (ACL). Dette mønsteret kan referere til en løsning for en eldre migrasjon (ved å innføre et mellomlag mellom det gamle og det nye systemet for å forhindre datakvalitetsproblemer etc.). Men i vår sammenheng når vi snakker om korrupsjon er det relatert til datamodellering gjeld du kan introdusere for å løse kortsiktige problemer.
La oss ta eksemplet på to systemer som har ansvaret for å administrere en gitt tilstand AV EN PLM-del(en del er et fysisk element produsert eller kjøpt og deretter montert som en helikopterrotor for eksempel). Ett eldre system (La Oss kalle Det SystemA) er ansvarlig for å administrere designfasen, og du må implementere et nytt system (La Oss kalle Det SystemZ) ansvarlig for å administrere vedlikeholdsfasen. Hele it-applikasjonslandskapet deler samme felles delidentifikator (partId) bortsett Fra SystemA som ikke er klar over Det. I Stedet for partId, Administrerer SystemA sin egen identifikator, systemAId. Fordi SystemZ må ringe SystemA ved hjelp av systemAId, kan en heuristisk være å integrere systemAId som en del Av SystemZ-datamodellen.
dette er en vanlig feil du bør unngå. Du ødela bare datamodellen din på grunn av en kortsiktig situasjon.
ACL-mønsteret kunne ha vært en løsning her. SystemZ kunne ha implementert sitt eget dataformat (uten ekstern korrupsjon som systemAId). Da ville det vært opp til et mellomlag for å håndtere oversettelsen mellom partId og systemAId.
Brukt på vårt emne, acl-mønsteret håndhever å implementere et lag mellom to forskjellige avgrensede sammenhenger. En komponent er ikke klar over hvordan man kaller en annen komponent som ikke er en del av sin egen avgrensede kontekst. I stedet er en komponent bare klar over hvordan man kartlegger sin egen datastruktur på dataformatet til den avgrensede konteksten den tilhører.
Forresten, Dette er en tommelfingerregel. En komponent skal tilhøre bare en avgrenset kontekst. DETTE er også GRUNNEN TIL AT DDD er en flott passform for mikrotjenestearkitektur. På grunn av den finkornede granulariteten er det lettere å overholde denne regelen.
for å oppsummere, bør en kanonisk modell som sådan betraktes som et anti-mønster i de fleste tilfeller. Du bør prøve å implementere det begrensede kontekstkonseptet som betyr en modell per kontekst med eksplisitte grenser mellom sammenhenger. To komponenter som er en del av ulike avgrensede sammenhenger bør kommunisere gjennom En Anti-Korrupsjon Lag for å hindre datamodellering korrupsjon.