Nylig har Det vært en ny endring forslag Til Cassandra indeksering som forsøker å redusere avveiningen mellom brukervennlighet og stabilitet: Gjør WHERE klausulen mye mer interessant og nyttig for sluttbrukere. Denne nye metoden kalles Storage-Attached Indexing (Sai). Det er ikke det flotteste navnet, men hva forventer du? Ingeniører er ikke kjent for å navngi ting, men kul teknologi er aldri en vits. SAI har fanget Oppmerksomheten Til Cassandra samfunnet, men hvorfor? Indeksering av data er ikke et nytt konsept i databaseverdenen.
hvordan vi indekserer dataene våre kan endres over tid basert på ønskede brukstilfeller og distribusjonsmodeller. Cassandra ble bygget kombinere aspekter Av Dynamo Og Stort Bord for å redusere kompleksiteten i lese og skrive overhead ved å holde ting enkelt. Kompleksiteten I Cassandra har vært mest reservert til sin distribuert natur og som et resultat, skapte en avveining for utviklere. Hvis du vil ha den utrolige skalaen Til Cassandra, må du bruke tiden på å lære å datamodell. Databaseindekser er ment å forbedre datamodellen og gjøre spørringene mer effektive. For Cassandra har De eksistert i noen form siden prosjektets tidlige dager. Den uheldige virkeligheten er at de ikke har matchet godt med brukerkrav. Enhver bruk av indeksering kommer med en lang liste over avvik og advarsler til det punktet at de for det meste unngås, og for noen, bare et hardt nei. Som et resultat har brukerne lært å datamodell med grunnleggende spørringer for å få best mulig ytelse.
de dagene kan komme bak oss, og funksjoner SOM SAI hjelper oss med å komme dit.
Sekundære indekser i distribuerte databaser
Ikke alle indekser er skapt like. Primære indekser er også kjent som den unike nøkkelen, Eller i Cassandra vokabular, partition key. Som en primær tilgangsmetode på databasen bruker Cassandra partisjonsnøkkelen til å identifisere noden som holder dataene og datafilen som lagrer partisjonen av data. Primær indeks leser I Cassandra er ganske enkel, men utenfor rammen av denne artikkelen. Du kan lese mer om dem her.
Sekundære indekser skaper en helt annen og unik utfordring i en distribuert database. La oss se på et eksempeltabell for å gjøre noen punkter:
OPPRETT TABELLBRUKERE (
id lang,
fornavn tekst,
etternavn tekst,
land tekst,
opprettet tidsstempel,
PRIMÆRNØKKEL (id)
);
et primært indeksoppslag ville være ganske enkelt slik:
VELG fornavn, etternavn FRA brukere der id = 100;
Hva om jeg ønsket å finne alle I Frankrike? Som noen kjent MED SQL, forventer du at denne spørringen skal fungere:
VELG fornavn, etternavn fra brukere der country = ‘FR’;
uten å opprette en sekundær indeks I Cassandra, vil denne spørringen mislykkes. Det grunnleggende tilgangsmønsteret I Cassandra er ved partisjonsnøkkel. I en ikke-distribuert database som en tradisjonell RDBMS, er hver kolonne av tabellen lett synlig for systemet. Du kan fortsatt få tilgang til kolonnen selv om det ikke er noen indeks siden de alle finnes i samme system og datafiler. Indekser i dette tilfellet bidra til å redusere spørringen tid ved å gjøre oppslaget mer effektiv.
i et distribuert system som Cassandra er kolonneverdiene på hver datanode og må inkluderes i spørringsplanen. Dette setter opp det vi kaller «Scatter-Samle» – scenariet der en spørring sendes til hver node, data samles inn, slås sammen og returneres til brukeren. Selv om denne operasjonen kan gjøres over flere noder samtidig, er ventetid ledelsen ned til hvor fort noden kan finne kolonneverdien.
Rask gjennomgang Av Cassandra data skriver
du kan tenke at å legge til indekser handler om å lese data, noe som absolutt er sluttmålet. Men når man bygger en database, er de tekniske utfordringene ved indeksering partisk på det punktet der data skrives. Å akseptere dataene med den raskeste hastigheten mens du formaterer indeksene i den mest optimale formen for leser, er en stor utfordring. Det er verdt å gjøre en rask gjennomgang av hvordan data skrives i En Cassanda-database på det enkelte nodenivå. Se følgende diagram som jeg forklarer hvordan det fungerer.
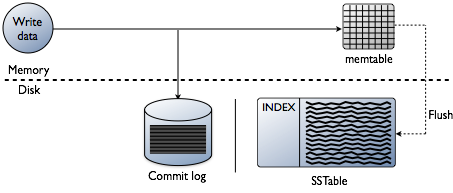
når data presenteres til en node, som vi kaller en mutasjon, er skrivebanen for Cassandra veldig enkel og optimalisert for den operasjonen. Dette gjelder også for mange andre databaser basert På Log-Structured Merge (LSM) trær.
- Valider data er riktig format. Skriv inn sjekk mot skjemaet.
- Skriv data inn i halen av en innføringslogg. Ingen søker, bare det neste stedet på filpekeren.
- Skriv data inn i en memtable, som bare er en hashmap av skjemaet i minnet.
Ferdig! Mutasjonen er anerkjent når disse tingene skjer. Jeg elsker hvor enkelt dette er i forhold til andre databaser som krever en lås og søker å utføre en skrive.
Senere, som memtables fylle fysisk minne, skriver en flush prosess ut segmenter i en enkelt pass på disken til en fil som kalles En Sstable (Sortert Strenger Tabell). Den medfølgende innleggingsloggen slettes nå som utholdenheten har flyttet til SSTable. Denne prosessen fortsetter å gjenta når data skrives til noden.
Viktig detalj: SSTables er uforanderlige. Når de er skrevet, blir de aldri oppdatert, bare erstattet. Til slutt, som flere data er skrevet, en bakgrunnsprosess som kalles komprimering fusjonerer og sorterer sstables i nye som også er uforanderlige. Det er mange komprimeringsordninger, men fundamentalt utfører de alle denne funksjonen.
Du har nå nok grunnleggende grunnlag på Cassandra, slik at vi kan bli tilstrekkelig nerdete med indekser. Ytterligere dybde av informasjon er igjen som en øvelse for leseren.
Problemer med tidligere indeksering
Cassandra har hatt to tidligere sekundære indekseringsimplementeringer. Lagring Vedlagt Sekundær Indeksering (SASI) og Sekundære Indekser, som vi refererer til som 2i. igjen, mitt poeng om ingeniører som ikke er prangende med navn, holder opp her. Sekundære indekser har vært En del Av Cassandra fra begynnelsen, men implementeringene har gjort dem plagsomme for sluttbrukere med sin lange liste over avvik. De to viktigste bekymringene vi hele tiden har jobbet med som et prosjekt, er skriveforsterkning og indeksstørrelse på disk. Som et resultat kan de være frustrerende fristende for nye brukere bare for å få dem til å mislykkes senere i distribusjonen. La oss se på hver.
Sekundære Indekser (2i) – dette originale arbeidet i prosjektet startet som en praktisk funksjon for tidlige Sparsommelig datamodeller. Senere, Da Cassandra Query Language erstattet Sparsommelighet som den foretrukne søkemetoden For Cassandra, ble 2i-funksjonaliteten beholdt med» CREATE INDEX » – syntaksen. Hvis DU hadde kommet fra SQL, var dette en veldig enkel måte å lære loven om utilsiktede konsekvenser. Akkurat som I SQL-indeksering, jo mer du legger til, desto mer påvirker du skriveytelsen. Men Med Cassandra utløste dette det større problemet med skriveforsterkning. Med henvisning til skrivebanen ovenfor la Sekundære Indekser et nytt skritt inn i banen. Når en mutasjon på en indeksert kolonne oppstår, utløses en indekseringsoperasjon som reindekserer data i en egen indeksfil. Flere indekser pa et bord kan dramatisk oke diskaktiviteten i en enkelt rad skriveoperasjon. Når en node tar en høy mengde mutasjoner, kan resultatet være mettet diskaktivitet som kan gjøre de enkelte noder ustabile, noe som gir 2i den fortjente veiledningen av » bruk sparsomt.»Indeksstørrelsen er ganske lineær i denne implementeringen, men med reindeksering kan mengden diskplass som trengs være vanskelig å planlegge for i en aktiv klynge.
Storage Attached Secondary Indexing (Sasi) — SASI ble opprinnelig designet av Et lite team Hos Apple for å løse et bestemt spørringsproblem og ikke det generelle problemet med sekundære indekser. For å være rettferdig mot det laget, kom det bort fra dem i et brukstilfelle som det aldri var designet for å løse. Velkommen til open source alle. De to spørretyper SOM SASI er utformet for å løse:
- Finne rader basert på delvis datamatching. Wildcard, ELLER lignende spørringer.
- Områdespørringer på sparsomme data, spesielt tidsstempler. Hvor mange poster passer i en tidsintervall type spørringer.
Det gjorde begge disse operasjonene ganske bra,og det tok også opp spørsmålet om skriveforsterkning med legacy 2i. som mutasjoner presenteres for En Cassandra-node, blir dataene indeksert i minnet under den første skrivingen, akkurat som hvordan memtables brukes. Ingen disk aktivitet er nødvendig på en permutasjon. En stor forbedring på klynger med mye skriveaktivitet. Når memtables tømmes til sstables, er den tilsvarende indeksen for dataene tømmes. Hver indeksfil skrevet er uforanderlig og festet til sstable, derav navnet Lagring Vedlagt. Når komprimeringen skjer, data er reindexed og skrevet til en ny fil som nye sstables opprettes. Fra et diskaktivitetsperspektiv var dette en stor forbedring. Ulempen AV SASI var hovedsakelig i størrelsen på indeksene opprettet. Indeksformatet på disken forårsaket en enorm mengde diskplass brukt for hver kolonne indeksert. Dette gjør dem svært vanskelig å administrere for operatører. I tillegg BLE SASI merket som eksperimentell og ikke mye har skjedd med hensyn til funksjonsforbedring. Mange feil har blitt funnet over tid med dyre reparasjoner som har ført til diskusjonen om HVORVIDT SASI skal fjernes helt. Hvis du trenger det dypeste dykket på denne funksjonen, Gjorde Duy Hai Doan en fantastisk jobb med å bryte ned HVORDAN SASI fungerer.
Hva gjør SAI bedre
det første, beste svaret på det spørsmålet er AT SAI er evolusjonær i naturen. Ingeniører ved DataStax innså at kjernearkitekturen For Sekundær Indeksering måtte tas opp fra grunnen, men med solide leksjoner som har blitt lært fra tidligere implementeringer. Adressering spørsmål om skrive-forsterkning og indeks filstørrelse mens du oppretter en bane for bedre spørring forbedringer I Cassandra har vært den primære oppgave. Hvordan adresserer SAI begge disse emnene?
Skriveforsterkning – som VI lærte AV SASI, var in-memory indeksering og flushing indekser med SSTables den riktige måten å holde seg i tråd med Hvordan Cassandra-skrivebanen fungerer, mens du legger til ny funksjonalitet. MED SAI, når mutasjonen er anerkjent, noe som betyr fullt engasjert, blir dataene indeksert. Med optimaliseringer og mye testing har effekten på skriveytelsen blitt betydelig forbedret. Du bør se bedre enn en 40% økning i gjennomstrømning og over 200% bedre skrive latenser enn 2i. Når det er sagt, bør du fortsatt planlegge en økning på 2x latens og gjennomstrømning på indekserte tabeller sammenlignet med ikke-indekserte tabeller. For Å sitere Duy Hai Doan, «Det er ingen magi,» bare god engineering.
Indeksstørrelse-Dette er den mest dramatiske forbedringen og uten tvil der mest arbeid er gjort. Hvis du følger en verden av database internals, vet du at datalagring er fortsatt et livlig felt fylt med kontinuerlig utvikling forbedringer. SAI bruker to forskjellige typer indekseringsordninger basert på datatypen.
- Tekst – Inverterte indekser opprettes med vilkår brutt inn i en ordbok. Den største forbedringen er fra bruk Av Trie basert indeksering som gir mye bedre komprimering som betyr mindre indeksstørrelser.
- Numerisk – Ved Hjelp av en datastruktur kalt block kd-trees, hentet Fra Lucene, som tilbyr utmerket utvalg spørring ytelse. En egen rad-ID-liste opprettholdes for å optimalisere for tokenordrespørringer.
med sterk vekt på indekslagring, var resultatet en massiv forbedring i volumet mot antall tabellindekser. Som du kan se i grafen nedenfor, ble den raske indekseringen brakt AV SASI raskt formørket av eksplosjonen av diskbruk. Ikke bare gjør det operasjonell planlegging en smerte, men indeksfilene måtte leses under komprimeringshendelser som kunne mette disker som førte til node ytelsesproblemer.
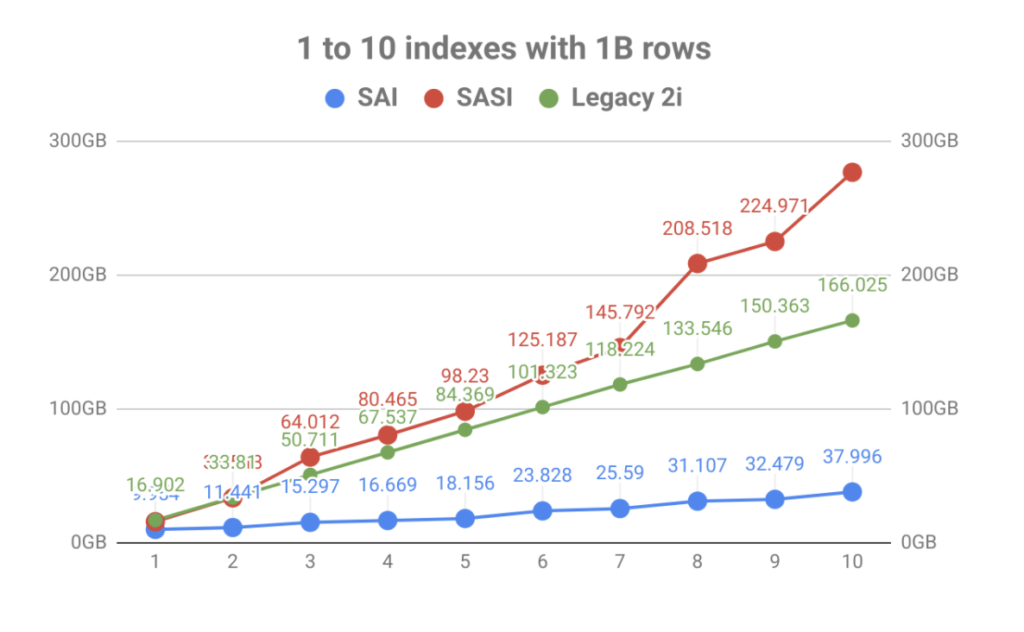
Utenfor skriveforsterkning og indeksstørrelse, gir den interne arkitekturen TIL SAI ytterligere utvidelse og ekstra funksjonalitet i fremtiden. Dette er i tråd med prosjektets mål om å bli mer modulære i fremtidige bygg. Ta en titt på noen av de andre CEPs som venter, og du kan se at dette bare er begynnelsen.
Hvor går SAI herfra?
DataStax har tilbudt Sai Til Apache Cassandra-prosjektet gjennom Cassandra Enhancement Process SOM CEP-7. Diskusjonen er på nå for inkludering i 4.x gren Av Cassandra.
hvis du vil prøve dette nå før Det er En Del Av Apache Cassandra-prosjektet, har vi et par steder for deg å gå. For operatører eller folk som liker litt mer teknisk hands-on, kan du laste ned den nyeste DataStax Enterprise 6.8. HVIS DU er en utvikler, ER SAI nå aktivert I DataStax Astra, Vår Cassandra som En Tjeneste. Du kan opprette et gratis-evig nivå for å leke med syntaks og ny where-klausulfunksjonalitet. Med det, lære å bruke denne funksjonen ved å gå Til Cassandra Indeksering Ferdigheter Siden og inkludert dokumentasjon.