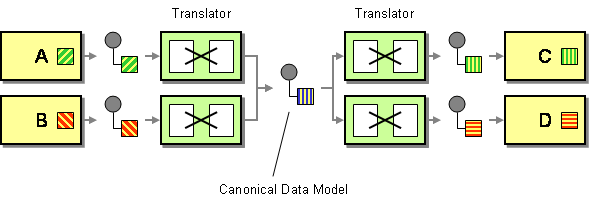
Un modèle de données canonique est défini dans les modèles d’intégration d’entreprise comme la solution permettant de minimiser les dépendances lors de l’intégration d’applications utilisant différents formats de données. En d’autres termes, un composant (une application ou un service) devrait communiquer avec un autre composant via un format de données qui serait indépendant des deux formats de données du composant.
Deux choses à souligner ici. J’ai d’abord défini un composant comme une application ou un service car de tels modèles sont / ont été utilisés dans le contexte de l’intégration des applications et de l’orientation des services. Deuxièmement, nous parlons ici d’un concept qui devrait être utilisé uniquement comme format de données de transport. Vous ne devez pas utiliser un format de données canonique comme structure interne de votre magasin de données.
Théoriquement, les avantages sont assez évidents. Un format de données canonique réduit le couplage entre les applications, réduit le nombre de traductions à développer pour intégrer un ensemble de composants, etc. Assez intéressant non? Un modèle de données unique est compréhensible par l’ensemble du paysage informatique et un ensemble de personnes (développeurs, analystes système, parties prenantes métier, etc.) qui peuvent partager la même vision d’un concept donné.
Pour des raisons pratiques, la mise en œuvre de tels modèles est cependant rarement efficace.
Une personne n’est pas le même concept pour le service marketing et support d’une compagnie d’assurance. Un vol pour un système de gestion du trafic aérien a une signification différente selon qu’il a été effectué par un pilote ou s’il s’agit d’un vol en cours au-dessus de votre espace aérien. Une pièce PLM a une représentation complètement différente selon qu’elle vient d’être conçue ou qu’elle doit être entretenue par une équipe de support.
Dans la plupart des contextes, la conception d’un modèle de données canonique aboutit à un modèle de données volumineux avec un ensemble complet d’attributs facultatifs et très peu d’attributs obligatoires (comme les identifiants). Même s’il a été principalement conçu pour faciliter l’intégration des composants, vous ne ferez que la compliquer. En attendant, votre modèle créera beaucoup de frustration parmi les utilisateurs en raison de sa complexité inhérente (en termes d’utilisation et de gestion). De plus, en ce qui concerne le problème de couplage, vous le déplacez simplement ailleurs. Au lieu d’être couplé à un format de données composant, vous devenez étroitement couplé à un format de données commun qui sera utilisé par l’ensemble du paysage informatique et sujet à des changements très fréquents.
En un mot, dans la plupart des contextes, un modèle de données canonique doit être considéré comme un anti-modèle. Quelle est l’autre option que de considérer que vous devriez toujours vouloir minimiser les dépendances entre deux composants échangeant des données?
Domain Driven Design (DDD) recommande d’introduire le concept de contexte borné. Un contexte borné est simplement un contexte explicite dans lequel un modèle s’applique avec des limites claires avec d’autres contextes bornés. Selon votre organisation, un contexte borné peut faire référence à un domaine fonctionnel dans lequel un objet est utilisé, il peut faire référence à l’état de l’objet lui-même, etc.
Dans ce cas, le modèle de données canoniques en tant que tel serait simplement la partie jaune du diagramme suivant:
L’intersection de A, B et C représente l’ensemble des attributs qui doivent être présents quel que soit le contexte (essentiellement les attributs obligatoires du grand CDM précédent). Cette partie doit encore être soigneusement conçue en raison de son rôle central. Pourtant, il est important de rester pragmatique. Si, dans votre contexte, il n’a pas de sens d’avoir un modèle aussi commun, vous devez simplement le jeter.
Ce qui est également important, c’est une intersection entre deux contextes (A et B, B et C, C et A). Comment mapper une représentation d’objet d’un contexte à un autre ? Quels sont les attributs explicites qui devraient être partagés dans deux contextes ? Quelles sont les contraintes commerciales communes entre deux contextes ? Une équipe transversale devrait toujours répondre à ces questions, mais d’un point de vue commercial, il est logique de les soulever. Cela n’a pas toujours été le cas avec un seul MDP partagé dans des contextes potentiellement opposés.
Néanmoins, en ce qui concerne les parties qui ne sont pas partagées avec d’autres contextes (en blanc), il ne devrait pas faire partie d’un modèle de données d’entreprise. Vous devriez être pragmatique. Par exemple, si un sous-ensemble est spécifique à un domaine donné, ce devrait être aux experts du domaine de le modéliser eux-mêmes.
Un défi clé, cependant, est d’identifier ces contextes bornés et il pourrait être utile de rappeler ici la loi de Conway:
Toute organisation qui conçoit un système produira inévitablement un design dont la structure est une copie de la structure de communication de l’organisation.
Les contextes bornés ne doivent pas nécessairement être mappés sur l’organisation actuelle. Par exemple, un contexte borné peut englober plusieurs départements. Briser les silos organisationnels devrait toujours être un objectif pour la plupart des entreprises.
De plus, DDD introduit le concept de Couche Anti-corruption (ACL). Ce modèle peut faire référence à une solution pour une migration héritée (en introduisant une couche d’intermédiation entre l’ancien et le nouveau système pour éviter les problèmes de qualité des données, etc.). Mais dans notre contexte, lorsque nous parlons de corruption, c’est lié à la modélisation des données de la dette que vous pouvez introduire pour résoudre des problèmes à court terme.
Prenons l’exemple de deux systèmes chargés de gérer un état donné d’une pièce PLM (une pièce est un objet physique produit ou acheté puis assemblé comme un rotor d’hélicoptère par exemple). Un système existant (appelons-le SystemA) est chargé de gérer la phase de conception et vous devez implémenter un nouveau système (appelons-le SystemZ) chargé de gérer la phase de maintenance. L’ensemble du paysage d’applications informatiques partage le même identifiant de partie commun (partId), à l’exception de SystemA qui n’en a pas connaissance. Au lieu du partId, SystemA gère son propre identifiant, systemAId. Comme SystemZ doit être appelé SystemA à l’aide de systemAId, une heuristique pourrait consister à intégrer systemAId dans le modèle de données SystemZ.
C’est une erreur courante que vous devez éviter. Vous avez simplement corrompu votre modèle de données en raison d’une situation à court terme.
Le modèle ACL aurait pu être une solution ici. SystemZ aurait pu implémenter son propre format de données (sans aucune corruption externe comme le systemAId). Ensuite, il aurait fallu une couche d’intermédiation pour gérer la traduction entre le partId et le systemAId.
Appliqué à notre sujet, le modèle ACL s’impose pour implémenter une couche entre deux contextes bornés différents. Un composant ne sait pas comment appeler un autre composant qui ne fait pas partie de son propre contexte borné. Au lieu de cela, un composant ne sait comment mapper sa propre structure de données que sur le format de données du contexte borné auquel il appartient.
Au fait, c’est une règle empirique. Un composant ne doit appartenir qu’à un seul contexte borné. C’est aussi pourquoi DDD convient parfaitement à l’architecture des microservices. En raison de la granularité à grain fin, il est plus facile de respecter cette règle.
Pour résumer, un modèle canonique en tant que tel doit être considéré comme un anti-modèle dans la plupart des cas. Vous devez essayer d’implémenter le concept de contexte borné, c’est-à-dire un modèle par contexte avec des limites explicites entre les contextes. Deux composants qui font partie de contextes délimités différents devraient communiquer via une couche Anti-corruption pour empêcher la corruption de la modélisation des données.