Récemment, il y a eu une nouvelle proposition de changement pour l’indexation Cassandra qui tente de réduire le compromis entre convivialité et stabilité: Rendre la clause WHERE beaucoup plus intéressante et utile pour les utilisateurs finaux. Cette nouvelle méthode s’appelle l’indexation liée au stockage (SAI). Ce n’est pas le nom le plus flashy, mais à quoi vous attendez-vous? Les ingénieurs ne sont pas connus pour nommer les choses, mais la technologie cool n’est jamais une blague. SAI a attiré l’attention de la communauté Cassandra, mais pourquoi? L’indexation des données n’est pas un concept nouveau dans le monde des bases de données.
La façon dont nous indexons nos données peut changer au fil du temps en fonction des cas d’utilisation et des modèles de déploiement souhaités. Cassandra a été construit en combinant les aspects de Dynamo et de Big Table pour réduire la complexité de la lecture et de l’écriture en gardant les choses simples. La complexité de Cassandra a été principalement réservée à sa nature distribuée et, par conséquent, a créé un compromis pour les développeurs. Si vous voulez l’échelle incroyable de Cassandra, vous devez passer du temps à apprendre à modéliser des données. Les index de base de données sont destinés à améliorer votre modèle de données et à rendre vos requêtes plus efficaces. Pour Cassandra, ils existent sous une forme ou une autre depuis les premiers jours du projet. La réalité malheureuse est qu’ils ne correspondent pas bien aux besoins des utilisateurs. Toute utilisation de l’indexation s’accompagne d’une longue liste de compromis et d’avertissements au point qu’ils sont pour la plupart évités et pour certains, juste un non difficile. En conséquence, les utilisateurs ont appris à modéliser les données avec des requêtes de base pour obtenir les meilleures performances.
Ces jours sont peut-être derrière nous et des fonctionnalités comme SAI nous aident à y arriver.
Index secondaires dans les bases de données distribuées
Tous les index ne sont pas créés égaux. Les index primaires sont également connus sous le nom de clé unique, ou dans le vocabulaire de Cassandra, clé de partition. En tant que méthode d’accès principale à la base de données, Cassandra utilise la clé de partition pour identifier le nœud contenant les données puis le fichier de données qui stocke la partition de données. Les lectures d’index primaires dans Cassandra sont assez simples mais dépassent le cadre de cet article. Vous pouvez en savoir plus à leur sujet ici.
Les index secondaires créent un défi complètement différent et unique dans une base de données distribuée. Regardons un exemple de table pour faire quelques points:
CRÉER des utilisateurs de TABLE (
id long,
Texte du prénom,
Texte du nom de famille,
texte du pays,
horodatage créé,
CLÉ PRIMAIRE (id)
);
Une recherche d’index primaire serait assez simple comme ceci:
SÉLECTIONNEZ LE prénom, le nom DES utilisateurs OÙ id = 100;
Et si je voulais trouver tout le monde en France? En tant que personne familière avec SQL, vous vous attendez à ce que cette requête fonctionne:
SÉLECTIONNEZ FirstName, LastName FROM users WHERE country=’FR’;
Sans créer d’index secondaire dans Cassandra, cette requête échouera. Le modèle d’accès fondamental dans Cassandra est par clé de partition. Dans une base de données non distribuée comme un SGBDR traditionnel, chaque colonne de la table est facilement visible par le système. Vous pouvez toujours accéder à la colonne même s’il n’y a pas d’index car ils existent tous dans le même système et les mêmes fichiers de données. Les index dans ce cas aident à réduire le temps de requête en rendant la recherche plus efficace.
Dans un système distribué comme Cassandra, les valeurs de colonne se trouvent sur chaque nœud de données et doivent être incluses dans le plan de requête. Cela met en place ce que nous appelons le scénario « Scatter-Gather » où une requête est envoyée à chaque nœud, les données sont collectées, fusionnées et renvoyées à l’utilisateur. Même si cette opération peut être effectuée sur plusieurs nœuds à la fois, la gestion de la latence dépend de la vitesse à laquelle le nœud peut trouver la valeur de la colonne.
Examen rapide des écritures de données Cassandra
Vous pensez peut-être que l’ajout d’index consiste à lire des données, ce qui est certainement l’objectif final. Cependant, lors de la création d’une base de données, les défis techniques liés à l’indexation sont biaisés au moment où les données sont écrites. Accepter les données à la vitesse la plus rapide tout en formatant les index sous la forme la plus optimale pour les lectures est un énorme défi. Il vaut la peine de faire un examen rapide de la façon dont les données sont écrites dans une base de données Cassanda au niveau du nœud individuel. Reportez-vous au diagramme suivant pour expliquer comment cela fonctionne.
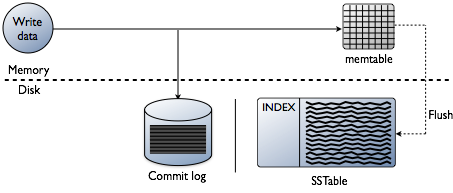
Lorsque des données sont présentées à un nœud, que nous appelons une mutation, le chemin d’écriture de Cassandra est très simple et optimisé pour cette opération. Cela est également vrai pour de nombreuses autres bases de données basées sur des arborescences de fusion structurées par journal (LSM).
- Valider les données est le format correct. Tapez la vérification par rapport au schéma.
- Écrivez des données dans la queue d’un journal de validation. Pas de recherche, juste l’endroit suivant sur le pointeur de fichier.
- Écrivez des données dans un memtable, qui n’est qu’un hashmap du schéma en mémoire.
C’est fait! La mutation est reconnue lorsque ces choses se produisent. J’aime la simplicité avec laquelle cela est comparé à d’autres bases de données qui nécessitent un verrou et cherchent à effectuer une écriture.
Plus tard, lorsque les tables de mémoire remplissent la mémoire physique, un processus de vidage écrit des segments en une seule passe sur le disque dans un fichier appelé SSTable (Table de chaînes triées). Le journal de validation qui l’accompagne est supprimé maintenant que la persistance a été déplacée vers la table SSTable. Ce processus ne cesse de se répéter lorsque les données sont écrites sur le nœud.
Détail important : Les tables SSTables sont immuables. Une fois qu’ils sont écrits, ils ne sont jamais mis à jour, juste remplacés. Finalement, au fur et à mesure que plus de données sont écrites, un processus d’arrière-plan appelé compactage fusionne et trie les tables sstables en de nouvelles qui sont également immuables. Il y a beaucoup de schémas de compactage, mais fondamentalement, ils remplissent tous cette fonction.
Vous avez maintenant assez de bases de base sur Cassandra pour que nous puissions être suffisamment ringards avec les index. Toute profondeur d’information supplémentaire est laissée comme un exercice pour le lecteur.
Problèmes liés à l’indexation précédente
Cassandra a eu deux implémentations d’indexation secondaires précédentes. Indexation secondaire attachée au stockage (SASI) et index secondaires, que nous appelons 2i. Encore une fois, mon point sur le fait que les ingénieurs ne sont pas flashy avec des noms tient ici. Les index secondaires font partie de Cassandra depuis le début, mais les implémentations les ont rendus gênants pour les utilisateurs finaux avec leur longue liste de compromis. Les deux principales préoccupations que nous avons constamment traitées en tant que projet sont l’amplification de l’écriture et la taille de l’index sur disque. En conséquence, ils peuvent être frustrants pour les nouveaux utilisateurs de ne les voir échouer que plus tard dans le déploiement. Regardons chacun.
Index secondaires (2i) — Ce travail original dans le projet a commencé comme une fonctionnalité de commodité pour les premiers modèles de données d’épargne. Plus tard, comme le langage de requête Cassandra a remplacé Thrift comme méthode de requête préférée pour Cassandra, la fonctionnalité 2i a été conservée avec la syntaxe « CREATE INDEX ». Si vous veniez de SQL, c’était un moyen très facile d’apprendre la loi des conséquences involontaires. Tout comme dans l’indexation SQL, plus vous ajoutez, plus vous affectez les performances d’écriture. Cependant, avec Cassandra, cela a déclenché le problème plus important de l’amplification en écriture. En se référant au chemin d’écriture ci-dessus, les index secondaires ont ajouté une nouvelle étape dans le chemin. Lorsqu’une mutation sur une colonne indexée se produit, une opération d’indexation est déclenchée qui réindexe les données dans un fichier d’index séparé. Plus d’index sur une table peuvent augmenter considérablement l’activité du disque en une seule opération d’écriture de ligne. Lorsqu’un nœud prend une grande quantité de mutations, le résultat peut être une activité de disque saturée qui peut rendre les nœuds individuels instables, donnant à 2i le guidage mérité de « utiliser avec parcimonie. »La taille de l’index est assez linéaire dans cette implémentation, mais avec la réindexation, la quantité d’espace disque nécessaire peut être difficile à planifier dans un cluster actif.
Indexation secondaire attachée au stockage (SASI) — SASI a été conçu à l’origine par une petite équipe d’Apple pour résoudre un problème de requête spécifique et non le problème général des index secondaires. Pour être juste avec cette équipe, cela leur a échappé dans un cas d’utilisation qu’elle n’a jamais été conçue pour résoudre. Bienvenue à tout le monde en open source. Les deux types de requêtes que SASI a été conçu pour traiter:
- Recherche de lignes en fonction de la correspondance partielle des données. Caractères génériques, ou requêtes SIMILAIRES.
- Requêtes de plage sur des données clairsemées, en particulier les horodatages. Combien d’enregistrements correspondent à des requêtes de type plage de temps.
Il a assez bien fait ces deux opérations et il a également résolu le problème de l’amplification d’écriture avec l’héritage 2i. Comme les mutations sont présentées à un nœud Cassandra, les données sont indexées en mémoire pendant l’écriture initiale, tout comme la façon dont les mémtables sont utilisées. Aucune activité de disque n’est requise lors d’une permutation. Une énorme amélioration sur les clusters avec beaucoup d’activité d’écriture. Lorsque les tables de mémoire sont vidées vers les tables s, l’index correspondant aux données est vidé. Chaque fichier d’index écrit est immuable et attaché au sstable, d’où le nom de stockage attaché. Lorsque le compactage se produit, les données sont réindexées et écrites dans un nouveau fichier au fur et à mesure de la création de nouvelles tables sstables. Du point de vue de l’activité du disque, il s’agissait d’une amélioration majeure. L’inconvénient de SASI résidait principalement dans la taille des indices créés. Le format d’index sur disque a généré une énorme quantité d’espace disque utilisé pour chaque colonne indexée. Cela les rend très difficiles à gérer pour les opérateurs. De plus, SASI a été considéré comme expérimental et il ne s’est pas passé grand-chose en ce qui concerne l’amélioration des fonctionnalités. De nombreux bogues ont été trouvés au fil du temps avec des corrections coûteuses qui ont amené la discussion sur la question de savoir si le SASI devait être complètement supprimé. Si vous avez besoin de la plongée la plus profonde sur cette fonctionnalité, Duy Hai Doan a fait un travail incroyable pour décomposer le fonctionnement de SASI.
Ce qui rend l’ISC meilleure
La première et la meilleure réponse à cette question est que l’ISC est de nature évolutive. Les ingénieurs de DataStax ont réalisé que l’architecture de base de l’indexation secondaire devait être abordée de fond en comble, mais avec de solides leçons tirées des implémentations précédentes. Résoudre les problèmes d’amplification d’écriture et de taille de fichier d’index tout en créant un chemin pour de meilleures améliorations des requêtes dans Cassandra a été la mission principale. Comment l’ISC aborde-t-elle ces deux sujets ?
Amplification d’écriture – Comme nous l’avons appris de SASI, l’indexation en mémoire et le rinçage des index avec SSTables étaient le bon moyen de rester en ligne avec le fonctionnement du chemin d’écriture Cassandra, tout en ajoutant de nouvelles fonctionnalités. Avec SAI, lorsque la mutation est reconnue, c’est-à-dire pleinement engagée, les données sont indexées. Grâce aux optimisations et à de nombreux tests, l’impact sur les performances d’écriture s’est considérablement amélioré. Vous devriez voir mieux qu’une augmentation de 40% du débit et plus de 200% de meilleures latences d’écriture sur 2i. Cela étant dit, vous devez toujours prévoir une augmentation de la latence et du débit 2x sur les tables indexées par rapport aux tables non indexées. Pour citer Duy Hai Doan, « Il n’y a pas de magie », juste une bonne ingénierie.
Taille de l’indice — C’est l’amélioration la plus spectaculaire et sans doute là où la plupart des travaux ont été effectués. Si vous suivez le monde des bases de données internes, vous savez que le stockage de données est toujours un domaine animé rempli d’améliorations en constante évolution. SAI utilise deux types différents de schémas d’indexation en fonction du type de données.
- Les index inversés de texte sont créés avec des termes séparés dans un dictionnaire. La plus grande amélioration provient de l’utilisation de l’indexation basée sur Trie qui offre une compression bien meilleure, ce qui signifie des tailles d’index plus petites.
- Numérique – Utilisant une structure de données appelée arbres kd de blocs, tirée de Lucene, qui offre d’excellentes performances de requête de plage. Une liste d’ID de ligne distincte est maintenue pour optimiser les requêtes d’ordre de jeton.
En mettant fortement l’accent sur le stockage d’index, le résultat a été une amélioration massive du volume par rapport au nombre d’index de table. Comme vous pouvez le voir dans le graphique ci-dessous, l’indexation rapide apportée par SASI a rapidement été éclipsée par l’explosion de l’utilisation du disque. Non seulement cela rend la planification opérationnelle pénible, mais les fichiers d’index devaient être lus pendant les événements de compactage, ce qui pouvait saturer les disques, entraînant des problèmes de performances des nœuds.
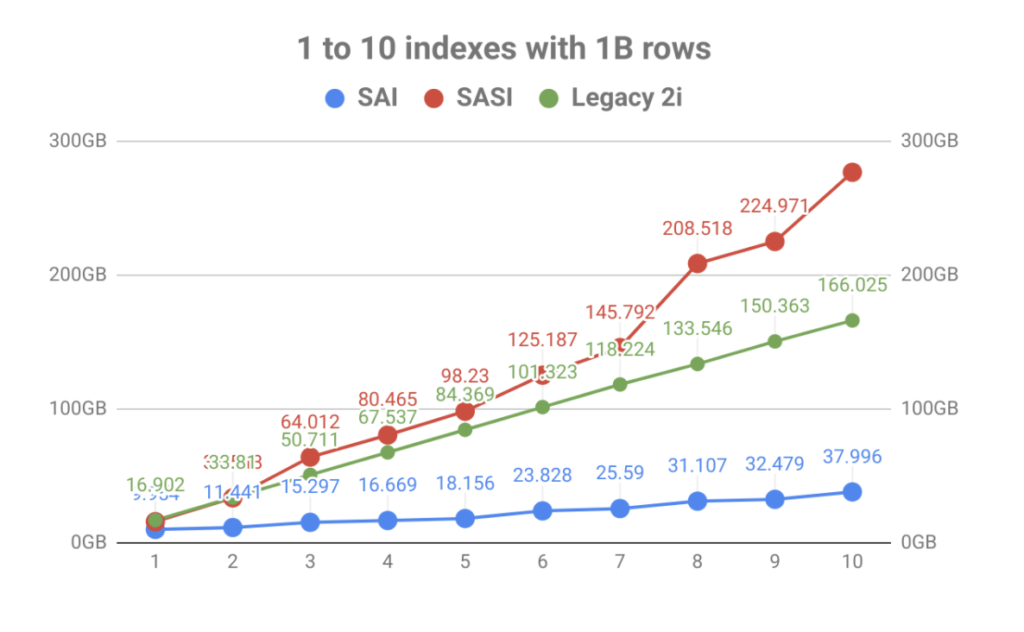
En dehors de l’amplification de l’écriture et de la taille de l’index, l’architecture interne de SAI permet une extension supplémentaire et des fonctionnalités supplémentaires à l’avenir. Ceci est conforme aux objectifs du projet d’être plus modulaire dans les futures constructions. Jetez un coup d’œil à certains des autres CÈPES en attente et vous pouvez voir que ce n’est que le début.
Où va SAI d’ici?
DataStax a proposé SAI au projet Apache Cassandra via le processus d’amélioration de Cassandra en tant que CEP-7. La discussion est maintenant ouverte pour inclusion dans le 4.branche x de Cassandre.
Si vous voulez essayer cela maintenant avant que cela fasse partie du projet Apache Cassandra, nous avons quelques endroits où vous pouvez aller. Pour les opérateurs ou les personnes qui aiment les pratiques un peu plus techniques, vous pouvez télécharger la dernière DataStax Enterprise 6.8. Si vous êtes un développeur, SAI est désormais activé dans DataStax Astra, notre Cassandra as a Service. Vous pouvez créer un niveau gratuit pour toujours pour jouer avec la syntaxe et les nouvelles fonctionnalités de la clause where. Avec cela, apprenez à utiliser cette fonctionnalité en accédant à la page des compétences d’indexation de Cassandra et à la documentation incluse.