L’optimisation est une technique de transformation de programme, qui tente d’améliorer le code en le faisant consommer moins de ressources (c’est-à-dire CPU, mémoire) et fournir une vitesse élevée.
En optimisation, les constructions de programmation générale de haut niveau sont remplacées par des codes de programmation de bas niveau très efficaces. Un processus d’optimisation de code doit suivre les trois règles données ci-dessous:
-
Le code de sortie ne doit en aucun cas modifier la signification du programme.
-
L’optimisation devrait augmenter la vitesse du programme et, si possible, le programme devrait exiger moins de ressources.
-
L’optimisation doit elle-même être rapide et ne doit pas retarder le processus de compilation global.
Des efforts pour un code optimisé peuvent être faits à différents niveaux de compilation du processus.
-
Au début, les utilisateurs peuvent modifier / réorganiser le code ou utiliser de meilleurs algorithmes pour écrire le code.
-
Après avoir généré du code intermédiaire, le compilateur peut modifier le code intermédiaire par des calculs d’adresse et des boucles d’amélioration.
-
Lors de la production du code machine cible, le compilateur peut utiliser une hiérarchie de mémoire et des registres CPU.
L’optimisation peut être classée en deux types : indépendante de la machine et dépendante de la machine.
Optimisation indépendante de la machine
Dans cette optimisation, le compilateur prend le code intermédiaire et transforme une partie du code qui n’implique aucun registre CPU et/ ou emplacement de mémoire absolu. Par exemple:
do{ item = 10; value = value + item; } while(valueThis code involves repeated assignment of the identifier item, which if we put this way:
Item = 10;do{ value = value + item; } while(valueshould not only save the CPU cycles, but can be used on any processor.
Machine-dependent Optimization
Machine-dependent optimization is done after the target code has been generated and when the code is transformed according to the target machine architecture. It involves CPU registers and may have absolute memory references rather than relative references. Machine-dependent optimizers put efforts to take maximum advantage of memory hierarchy.
Basic Blocks
Source codes generally have a number of instructions, which are always executed in sequence and are considered as the basic blocks of the code. These basic blocks do not have any jump statements among them, i.e., when the first instruction is executed, all the instructions in the same basic block will be executed in their sequence of appearance without losing the flow control of the program.
A program can have various constructs as basic blocks, like IF-THEN-ELSE, SWITCH-CASE conditional statements and loops such as DO-WHILE, FOR, and REPEAT-UNTIL, etc.
Basic block identification
We may use the following algorithm to find the basic blocks in a program:
-
Rechercher les instructions d’en-tête de tous les blocs de base à partir desquels commence un bloc de base:
- Première déclaration d’un programme.
- Instructions cibles de n’importe quelle branche (conditionnelle/inconditionnelle).
- Instructions qui suivent n’importe quelle instruction de branche.
-
Les instructions d’en-tête et les instructions qui les suivent forment un bloc de base.
-
Un bloc de base n’inclut aucune instruction d’en-tête d’un autre bloc de base.
Les blocs de base sont des concepts importants du point de vue de la génération de code et de l’optimisation.
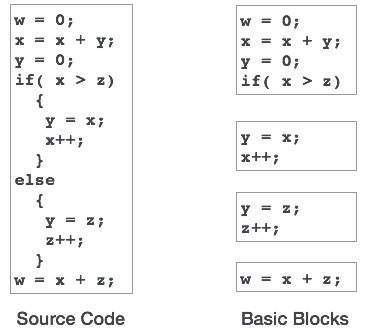
Les blocs de base jouent un rôle important dans l’identification des variables, qui sont utilisées plus d’une fois dans un seul bloc de base. Si une variable est utilisée plus d’une fois, la mémoire de registre allouée à cette variable n’a pas besoin d’être vidée à moins que le bloc ne termine l’exécution.
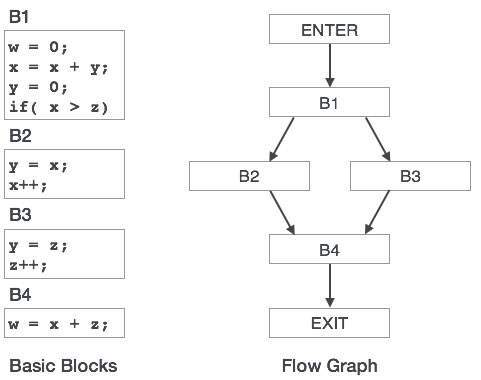
Graphique de flux de contrôle
Les blocs de base d’un programme peuvent être représentés au moyen de graphiques de flux de contrôle. Un graphique de flux de contrôle montre comment le contrôle du programme est passé entre les blocs. C’est un outil utile qui aide à l’optimisation en aidant à localiser les boucles indésirables dans le programme.
Optimisation de boucle
La plupart des programmes s’exécutent en boucle dans le système. Il devient nécessaire d’optimiser les boucles afin d’économiser des cycles CPU et de la mémoire. Les boucles peuvent être optimisées par les techniques suivantes:
-
Code invariant: Un fragment de code qui réside dans la boucle et calcule la même valeur à chaque itération est appelé code invariant en boucle. Ce code peut être déplacé hors de la boucle en l’enregistrant pour être calculé une seule fois, plutôt qu’à chaque itération.
-
Analyse d’induction : Une variable est appelée variable d’induction si sa valeur est modifiée dans la boucle par une valeur invariante à la boucle.
-
Réduction de la force : Certaines expressions consomment plus de cycles CPU, de temps et de mémoire. Ces expressions doivent être remplacées par des expressions moins chères sans compromettre la sortie de l’expression. Par exemple, la multiplication (x* 2) est coûteuse en termes de cycles CPU que (x
Élimination du code mort
Le code mort est une ou plusieurs instructions de code, qui sont:
- Soit jamais exécuté ou inaccessible,
- Ou s’il est exécuté, leur sortie n’est jamais utilisée.
Ainsi, le code mort ne joue aucun rôle dans aucune opération du programme et peut donc simplement être éliminé.
Code partiellement mort
Il existe certaines instructions de code dont les valeurs calculées ne sont utilisées que dans certaines circonstances, c’est-à-dire que parfois les valeurs sont utilisées et parfois elles ne le sont pas. Ces codes sont connus sous le nom de code partiellement mort.
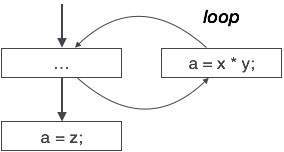
Le graphique de flux de contrôle ci-dessus représente un morceau de programme où la variable ‘a’ est utilisée pour attribuer la sortie de l’expression ‘x * y’. Supposons que la valeur attribuée à « a » ne soit jamais utilisée à l’intérieur de la boucle.Immédiatement après que le contrôle a quitté la boucle, ‘a’ reçoit la valeur de la variable ‘z’, qui sera utilisée plus tard dans le programme. Nous concluons ici que le code d’affectation de ‘a’ n’est jamais utilisé nulle part, il peut donc être éliminé.
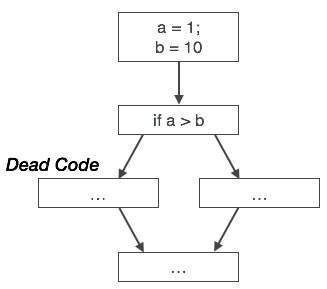
De même, l’image ci-dessus montre que l’instruction conditionnelle est toujours fausse, ce qui implique que le code, écrit dans le cas vrai, ne sera jamais exécuté, il peut donc être supprimé.
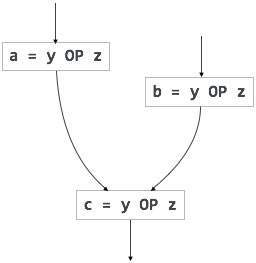
Redondance partielle
Les expressions redondantes sont calculées plus d’une fois en chemin parallèle, sans aucune modification des opérandes.alors que les expressions partiellement redondantes sont calculées plus d’une fois dans un chemin, sans aucune modification des opérandes. Par exemple,
|
|
Le code invariant en boucle est partiellement redondant et peut être éliminé en utilisant une technique de mouvement de code.
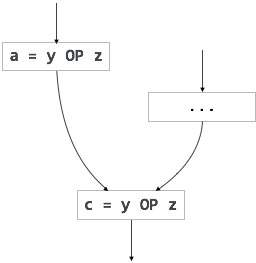
Un autre exemple de code partiellement redondant peut être:
If (condition){ a = y OP z;}else{ ...}c = y OP z;
Nous supposons que les valeurs des opérandes (y et z) ne sont pas modifiées de l’affectation de la variable a à la variable c. Ici, si l’instruction de condition est vraie, alors y OP z est calculé deux fois, sinon une fois. Le mouvement du code peut être utilisé pour éliminer cette redondance, comme indiqué ci-dessous:
If (condition){ ... tmp = y OP z; a = tmp; ...}else{ ... tmp = y OP z;}c = tmp;
Ici, si la condition est vraie ou fausse; y OP z ne doit être calculé qu’une seule fois.