dette er en trinvis vejledning i, hvordan du kører K-betyder klyngeanalyse på et regneark fra start til slut. Bemærk, at der er en skabelon, der automatisk kører klyngeanalyse, der kan hentes gratis på denne hjemmeside. Men hvis du vil vide, hvordan du kører en k-betyder klyngedannelse på udmærke dig selv, så er denne artikel noget for dig.
ud over denne artikel har jeg også en video gennemgang af, hvordan man kører klyngeanalyse.
- trin et-Start med dit datasæt
- trin To – hvis blot to variabler, bruge en scatter graf på udmærke
- trin tre – Beregn afstanden fra hvert datapunkt til midten af en klynge
- Hvordan fungerer beregningen?
- Trin fire-Beregn gennemsnittet (gennemsnittet) for hvert klyngesæt
- trin fem – Gentag trin 3-afstanden fra det reviderede gennemsnit
- afsluttende trin-graf og sammenfatte klyngerne
trin et-Start med dit datasæt
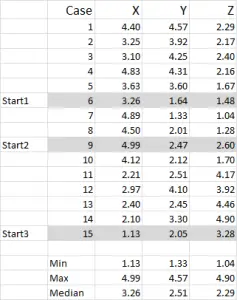
Figur 1
i dette eksempel bruger jeg 15 tilfælde (eller respondenter), hvor vi har dataene for tre variabler – generisk mærket H, Y og å.
du skal bemærke, at dataene skaleres 1-5 i dette eksempel. Dine data kan være i enhver form undtagen en nominel data skala (se artiklen om hvilke data der skal bruges).
Bemærk: Jeg foretrækker at bruge skalerede data-men det er ikke obligatorisk. Årsagen til dette er at” indeholde ” eventuelle outliers. Sig for eksempel, Jeg bruger indkomstdata (en demografisk foranstaltning) – de fleste af dataene kan være omkring $40.000 til $100.000, men jeg har en person med en indkomst på $5m. det er bare lettere for mig at klassificere den person i indkomstgruppen “over $250.000” og skalere indkomst 1-9 – men det er op til dig afhængigt af de data, du arbejder med.
du kan se fra dette eksempel sæt, at tre startpositioner er blevet fremhævet – vi vil diskutere dem i Trin tre nedenfor.
trin To – hvis blot to variabler, bruge en scatter graf på udmærke
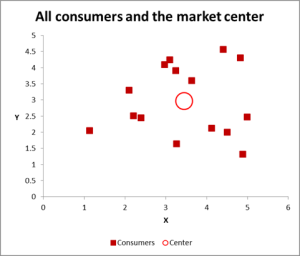
figur 2
i dette klyngeanalyseeksempel bruger vi tre variabler – men hvis du kun har to variabler til at klynge, så er et scatter chart en glimrende måde at starte på. Og til tider kan du klynge dataene via visuelle midler.
som du kan se i denne scatter graf, er hvert enkelt tilfælde (hvad jeg kalder en forbruger for dette eksempel) blevet kortlagt sammen med gennemsnittet (middel) for alle tilfælde (den røde cirkel).
afhængigt af hvordan du ser dataene/grafen – der ser ud til at være et antal klynger. I dette tilfælde kan du identificere tre eller fire relativt forskellige klynger – som vist i dette næste diagram.
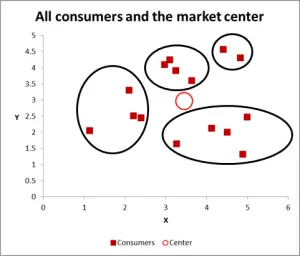
figur 3
med denne næste graf har jeg synligt identificeret sandsynlig klynge og cirkuleret dem. Som jeg har foreslået, en god tilgang, når der kun er to variabler at overveje – men er det tilfældet, har vi tre variabler (og du kunne have mere), så denne visuelle tilgang vil kun fungere for grundlæggende datasæt – så lad os nu se på, hvordan man gør beregningen af K-betyder klyngedannelse.
trin tre – Beregn afstanden fra hvert datapunkt til midten af en klynge
for dette gennemgangseksempel, lad os antage, at vi kun vil identificere tre segmenter/klynger. Ja, der er fire klynger tydelige i diagrammet ovenfor, men det ser kun på to af variablerne. Bemærk, at du kan bruge denne metode til at identificere så mange klynger, som du vil – bare følg det samme koncept som forklaret nedenfor.
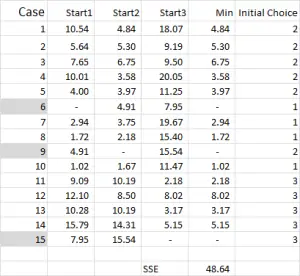
figur 4
for k-betyder klyngedannelse vælger du typisk nogle tilfældige tilfælde (udgangspunkt eller frø) for at få analysen startet.
i dette eksempel – da jeg ønsker at oprette tre klynger, så har jeg brug for tre udgangspunkt. Til disse startpunkter har jeg valgt sager 6, 9 og 15 – men eventuelle tilfældige punkter kan også være egnede.
årsagen til, at jeg valgte disse sager, er fordi – når man kun ser på variabel h – sag 6 var medianen, sag 9 var maksimum og sag 15 var minimum. Dette tyder på, at disse tre tilfælde er noget forskellige fra hinanden, så gode udgangspunkt som de er spredt ud.
se artiklen om, hvorfor klyngeanalyse undertiden genererer forskellige resultater.
med henvisning til tabellen output – dette er vores første beregning i udmærke sig, og det genererer vores “første valg” af klynger. Start 1 er data for sag 6, start 2 er Sag 9 og start 3 er Sag 15. Du skal bemærke, at skæringspunktet mellem hver af disse giver en 0 (-) i tabellen.
Hvordan fungerer beregningen?
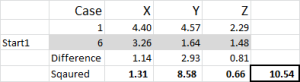
figur 5
lad os se på det første nummer i tabellen – sag 1, start 1 = 10.54.
Husk, at vi vilkårligt har udpeget sag 6 til at være vores tilfældige startpunkt for klynge 1. Vi ønsker at beregne afstanden, og vi bruger summen af kvadrater metode – som vist her. Vi beregner forskellen mellem hvert af de tre datapunkter i sættet og kvadrerer derefter forskellene og opsummerer dem derefter.
vi kan gøre det “mekanisk” som vist her – men vi har en indbygget formel til at bruge: SUMKSMY2-dette er langt mere effektivt at bruge.
når vi henviser tilbage til figur 4, finder vi derefter minimumsafstanden for hvert tilfælde fra hvert af de tre startpunkter – dette fortæller os, hvilken klynge (1, 2 eller 3) sagen er tættest på – som vises i kolonnen ‘indledende valg’.
Trin fire-Beregn gennemsnittet (gennemsnittet) for hvert klyngesæt
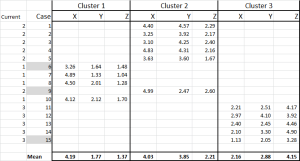
figur 6
vi har nu tildelt hver sag til sin oprindelige klynge-og vi kan lægge det ud ved hjælp af en IF-erklæring i en tabel (som vist i figur 6).
nederst i tabellen har vi gennemsnittet (gennemsnittet) af hvert af disse tilfælde. N0V-i stedet for kun at stole på et “repræsentativt” datapunkt – har vi et sæt sager, der repræsenterer hver.
trin fem – Gentag trin 3-afstanden fra det reviderede gennemsnit
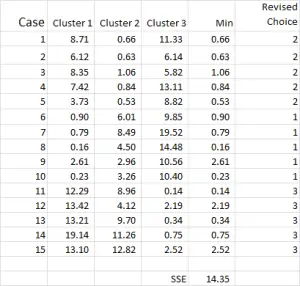
Figur 7
klyngeanalyseprocessen bliver nu et spørgsmål om at gentage trin 4 og 5 (iterationer), indtil klyngerne stabiliseres.
hver gang vi bruger det reviderede gennemsnit for hver klynge. Derfor viser figur 7 vores anden iteration – men denne gang bruger vi de midler, der genereres i bunden af figur 6 (i stedet for startpunkterne fra Figur 1).
du kan nu se, at der er sket en lille ændring i klyngeapplikationen, hvor sag 9 – et af vores udgangspunkt – omfordeles.
du kan også se summen af kvadreret fejl (SSE) beregnet i bunden – hvilket er summen af hver af de mindste afstande. Vores mål er nu at gentage trin 4 og 5, indtil SSE kun viser minimal forbedring, og/eller klyngeallokeringsændringerne er mindre på hver iteration.
afsluttende trin-graf og sammenfatte klyngerne
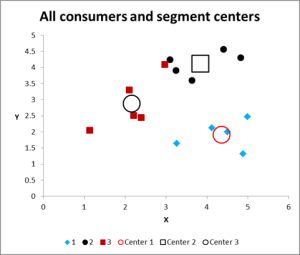
figur 8
efter at have kørt flere iterationer har vi nu output til at tegne og opsummere dataene.
her er outputgrafen for dette eksempel på klyngeanalyse.
som du kan se, er der tre forskellige klynger vist sammen med centroiderne (gennemsnittet) af hver klynge – de større symboler.
vi kan også præsentere disse data i en tabelform, hvis det er nødvendigt, som vi har udarbejdet det.
se sagen i klynge 3 – Den Lille Røde Firkant lige ved siden af den sorte prik øverst i midten af grafen. Denne sag sidder der på grund af indflydelsen fra den tredje variabel, som ikke er vist på dette to variable diagram.