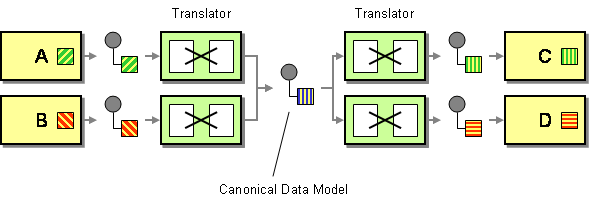
en kanonisk datamodel defineres i Virksomhedsintegrationsmønstre som løsningen til at minimere afhængigheder ved integration af applikationer, der bruger forskellige dataformater. Med andre ord skal en komponent (en applikation eller en tjeneste) kommunikere med en anden komponent gennem et dataformat, der ville være uafhængigt af begge komponentdataformater.
to ting at fremhæve her. Først definerede jeg en komponent som enten en applikation eller en tjeneste, fordi sådanne modeller er/blev brugt i forbindelse med applikationsintegration og serviceorientering. For det andet taler vi her om et koncept, der udelukkende skal bruges som et transportdataformat. Du bør ikke bruge et kanonisk dataformat som den interne struktur i din datalager.
teoretisk set er fordelene ret indlysende. Et kanonisk dataformat reducerer koblingen mellem applikationer, reducerer antallet af oversættelser, der skal udvikles til integration af et sæt komponenter osv. Temmelig interessant ret? En enkelt datamodel er forståelig af hele IT-landskabet og et sæt mennesker (udviklere, systemanalytikere, forretningsinteressenter osv.) hvem kan dele den samme vision om et givet koncept.
til praktiske formål er implementering af sådanne modeller sjældent effektiv.
en person er ikke det samme koncept for marketing-og supportafdelingen i et forsikringsselskab. En flyvning til et lufttrafikstyringssystem har en anden betydning, afhængigt af om den blev udfyldt af en pilot, eller om det er en løbende flyvning oven på dit luftrum. En PLM-del har en helt anden repræsentation, afhængigt af om den netop er designet, eller om den skal vedligeholdes af et supportteam.
i de fleste sammenhænge resulterer design af en kanonisk datamodel i en stor datamodel med et komplet sæt valgfrie attributter og meget få obligatoriske (som identifikatorerne). Selvom det primært var designet til at lette komponentintegration, vil du bare komplicere det. I mellemtiden vil din model skabe en masse frustration blandt brugerne på grund af dens iboende kompleksitet (med hensyn til udnyttelse og styring). Desuden, med hensyn til koblingsproblemet, du skifter det bare et andet sted. I stedet for at blive koblet til et komponentdataformat, bliver du tæt koblet til et fælles dataformat, der vil blive brugt af hele IT-landskabet og underlagt meget hyppige ændringer.
i en nøddeskal skal en kanonisk datamodel i de fleste sammenhænge betragtes som et anti-mønster. Hvad er den anden mulighed end at overveje, at du stadig ønsker at minimere afhængighederne mellem to komponenter, der udveksler data?
Domain Driven Design (DDD) anbefaler at introducere begrebet afgrænset kontekst. En afgrænset kontekst er simpelthen en eksplicit kontekst, hvor en model gælder med klare grænser med andre afgrænsede sammenhænge. Afhængigt af din organisation kan en afgrænset kontekst henvise til et funktionelt domæne, hvor et objekt bruges, det kan henvise til selve objekttilstanden osv.
i så fald ville den kanoniske datamodel som sådan simpelthen være den gule del i følgende diagram:
skæringspunktet mellem A, B og C repræsenterer det sæt attributter, der skal være der uanset konteksten (dybest set de obligatoriske attributter fra den tidligere store CDM). Denne del skal stadig være omhyggeligt designet på grund af dens centrale rolle. Men det er vigtigt at forblive pragmatisk. Hvis det i din sammenhæng ikke giver mening at have en sådan fælles model, skal du blot kassere den.
det, der også er vigtigt, er et kryds mellem to sammenhænge (A og B, B og C, C og a). Hvordan kortlægges en objektrepræsentation fra en kontekst til en anden? Hvad er de eksplicitte attributter, der skal deles på tværs af to sammenhænge? Hvad er de fælles forretningsbegrænsninger mellem to sammenhænge? Disse spørgsmål skal stadig besvares af et tværgående team, men fra et forretningsperspektiv er det fornuftigt at rejse dem. Det var ikke altid tilfældet med en enkelt CDM delt på tværs af potentielt modsatte sammenhænge.
hvad angår de dele, der ikke deles med andre sammenhænge (i hvidt), bør det ikke være en del af en virksomhedsdatamodel. Du skal være pragmatisk. For eksempel, hvis en delmængde er specifik for et givet domæne, skal det være op til domæneeksperterne at modellere det selv.
en vigtig udfordring er dog at identificere de afgrænsede sammenhænge, og det kan være værd at minde her om Conveyens lov:
enhver organisation, der designer et system, vil uundgåeligt producere et design, hvis struktur er en kopi af organisationens kommunikationsstruktur.
de afgrænsede sammenhænge skal ikke nødvendigvis kortlægges på den nuværende organisation. For eksempel kan en afgrænset kontekst omfatte flere afdelinger. At bryde organisatoriske siloer bør stadig være et mål for de fleste virksomheder.
derudover introducerer DDD begrebet Antikorruptionslag (ACL). Dette mønster kan henvise til en løsning til en ældre migration (ved at indføre et formidlingslag mellem Det Gamle og det nye system for at forhindre datakvalitetsproblemer osv.). Men i vores sammenhæng, når vi taler om korruption, er det relateret til datamodellering af gæld, du kan introducere for at løse kortsigtede problemer.
lad os tage eksemplet på to systemer, der har ansvaret for at styre en given tilstand af en PLM-del (en del er en fysisk vare produceret eller købt og derefter samlet som en helikopterrotor for eksempel). Et ældre system (lad os kalde det SystemA) har ansvaret for at styre designfasen, og du skal implementere et nyt system (lad os kalde det system), der har ansvaret for at styre vedligeholdelsesfasen. Hele IT-applikationslandskabet deler den samme fælles delidentifikator (partId) bortset fra SystemA, som ikke er opmærksom på det. I stedet for partId administrerer SystemA sin egen identifikator, systemAId. Da systemet skal kaldes SystemA ved hjælp af systemAId, kan en heuristisk være at integrere systemAId som en del af Systemdatamodellen.
dette er en almindelig fejl, du bør undgå. Du har simpelthen ødelagt din datamodel på grund af en kortsigtet situation.
ACL-mønsteret kunne have været en løsning her. Systemet kunne have implementeret sit eget dataformat (uden ekstern korruption som systemAId). Så ville det have været op til et formidlingslag at styre oversættelsen mellem partId og systemAId.
anvendt på vores emne håndhæver ACL-mønsteret at implementere et lag mellem to forskellige afgrænsede sammenhænge. En komponent er ikke klar over, hvordan man kalder en anden komponent, som ikke er en del af sin egen afgrænsede kontekst. I stedet er en komponent kun opmærksom på, hvordan man kortlægger sin egen datastruktur på dataformatet for den afgrænsede kontekst, den tilhører.
forresten er dette en tommelfingerregel. En komponent må kun tilhøre en afgrænset kontekst. Dette er også grunden til, at DDD er en god pasform til mikroservices arkitektur. På grund af den finkornede granularitet er det lettere at overholde denne regel.
for at opsummere bør en kanonisk model som sådan betragtes som et anti-mønster i de fleste tilfælde. Du bør forsøge at implementere det afgrænsede kontekstbegreb, der betyder en model pr. To komponenter, der er en del af forskellige afgrænsede sammenhænge, skal kommunikere gennem et Antikorruptionslag for at forhindre datamodellering af korruption.