for nylig har der været et nyt ændringsforslag til Cassandra indeksering, der forsøger at reducere afvejningen mellem brugervenlighed og stabilitet: gør hvor-klausulen meget mere interessant og nyttig for slutbrugere. Denne nye metode kaldes Storage-Attached indeksering (SAI). Det er ikke det prangende navn, men hvad forventer du? Ingeniører er ikke kendt for at navngive ting, men cool teknologi er aldrig en vittighed. SAI har fanget Cassandra-samfundets opmærksomhed, men hvorfor? Indeksering af data er ikke et nyt koncept i databaseverdenen.
hvordan vi indekserer vores data kan ændre sig over tid baseret på de ønskede brugssager og implementeringsmodeller. Cassandra blev bygget ved at kombinere aspekter af Dynamo og Big Table for at reducere kompleksiteten ved at læse og skrive overhead ved at holde tingene enkle. Kompleksiteten af Cassandra har for det meste været forbeholdt sin distribuerede natur og som et resultat skabt en afvejning for udviklere. Hvis du vil have den utrolige skala af Cassandra, skal du bruge tiden på at lære at datamodel. Databaseindekser er beregnet til at forbedre din datamodel og gøre dine forespørgsler mere effektive. For Cassandra har de eksisteret i en eller anden form siden projektets tidlige dage. Den uheldige virkelighed er, at de ikke har matchet godt med brugernes krav. Enhver brug af indeksering kommer med en lang liste over afvejninger og advarsler til det punkt, at de for det meste undgås og for nogle, bare et hårdt nej. Som et resultat har brugerne lært at datamodel med grundlæggende forespørgsler for at få den bedste ydelse.
disse dage kan komme bag os, og funktioner som SAI hjælper os med at komme derhen.
sekundære indekser i distribuerede databaser
ikke alle indekser oprettes ens. Primære indekser er også kendt som den unikke nøgle, eller i Cassandra ordforråd, partition nøgle. Som en primær adgangsmetode i databasen bruger Cassandra partitionsnøglen til at identificere noden, der holder dataene, og derefter datafilen, der gemmer partitionen af data. Primære indeks læser i Cassandra er forholdsvis enkel, men uden for rammerne af denne artikel. Du kan læse mere om dem her.
sekundære indekser skaber en helt anden og unik udfordring i en distribueret database. Lad os se på et eksempel tabel for at gøre et par punkter:
Opret tabel brugere (
id lang,
fornavn tekst,
efternavn tekst,
land tekst,
oprettet tidsstempel,
primær nøgle (id)
);
et primært indeksopslag ville være ret simpelt som dette:
vælg fornavn, efternavn fra brugere, hvor id = 100;
hvad hvis jeg ville finde alle i Frankrig? Som en person, der er bekendt med
vælg fornavn, efternavn fra brugere, hvor land = ‘FR’;
uden at oprette et sekundært indeks i Cassandra, vil denne forespørgsel mislykkes. Det grundlæggende adgangsmønster i Cassandra er ved partitionsnøgle. I en ikke-distribueret database som en traditionel RDBMS er hver kolonne i tabellen let synlig for systemet. Du kan stadig få adgang til kolonnen, selvom der ikke er noget indeks, da de alle findes i det samme system og datafiler. Indekser hjælper i dette tilfælde med at reducere forespørgselstiden ved at gøre opslag mere effektivt.
i et distribueret system som Cassandra er kolonneværdierne på hver dataknude og skal inkluderes i forespørgselsplanen. Dette opretter det, vi kalder “Scatter-Gather” – scenariet, hvor en forespørgsel sendes til hver node, data indsamles, flettes og returneres til brugeren. Selvom denne operation kan udføres over flere noder på en gang, er latensstyringen nede på, hvor hurtigt noden kan finde kolonneværdien.
hurtig gennemgang af Cassandra data skriver
du tænker måske, at tilføjelse af indekser handler om at læse data, hvilket bestemt er slutmålet. Men når man bygger en database, er de tekniske udfordringer ved indeksering forudindtaget på det punkt, hvor data skrives. At acceptere dataene med den hurtigste hastighed, mens du formaterer indekserne i den mest optimale form for læsning, er en enorm udfordring. Det er værd at lave en hurtig gennemgang af, hvordan data skrives i en Cassanda-database på det individuelle knudeniveau. Se følgende diagram, da jeg forklarer, hvordan det fungerer.
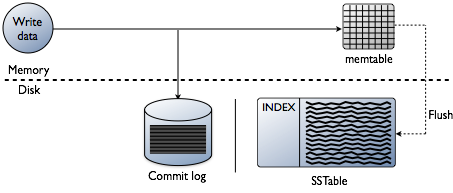
når data præsenteres for en node, som vi kalder en mutation, er skrivestien for Cassandra meget enkel og optimeret til den operation. Dette gælder også for mange andre databaser baseret på Logstrukturerede Fletningstræer(LSM).
- Valider data er det korrekte format. Skriv kontrol mod skemaet.
- skriv data i halen af en commit log. Ingen søger, bare det næste sted på filmarkøren.
- skriv data i en memtabel, som kun er en hashmap af skemaet i hukommelsen.
færdig! Mutationen anerkendes, når disse ting sker. Jeg elsker, hvor simpelt dette er sammenlignet med andre databaser, der kræver en lås og søger at udføre en skrivning.
senere, da memtables fylder fysisk hukommelse, skriver en flush-proces segmenter i en enkelt videregivelse af disk til en fil kaldet en Sstable (sorterede strenge tabel). Den ledsagende commit-log slettes nu, når persistensen er flyttet til SSTable. Denne proces fortsætter med at gentage, da data skrives til noden.
vigtig detalje: SSTables er uforanderlige. Når de er skrevet, bliver de aldrig opdateret, bare erstattet. Efterhånden som flere data skrives, smelter en baggrundsproces kaldet komprimering sammen og sorterer sstables til nye, som også er uforanderlige. Der er mange komprimeringsordninger, men grundlæggende udfører de alle denne funktion.
du har nu nok grundlæggende fundament på Cassandra, så vi kan få tilstrækkeligt nørdet med indekser. Enhver yderligere dybde af information er tilbage som en øvelse for læseren.
problemer med tidligere indeksering
Cassandra har haft to tidligere sekundære indekseringsimplementeringer. Opbevaring vedhæftet sekundær indeksering (SASI) og sekundære indekser, som vi omtaler som 2i. igen holder mit punkt om ingeniører, der ikke er prangende med navne, her. Sekundære indekser har været en del af Cassandra fra starten, men implementeringerne har gjort dem besværlige for slutbrugere med deres lange liste over afvejninger. De to største bekymringer, vi konstant har behandlet som et projekt, er skriveforstærkning og indeksstørrelse på disken. Som et resultat kan de være frustrerende fristende for nye brugere kun for at få dem til at mislykkes senere i implementeringen. Lad os se på hver.
sekundære indekser (2i) — dette originale arbejde i projektet startede som en bekvemmelighedsfunktion til tidlige sparsommelige datamodeller. Senere, da Cassandra-forespørgselssprog erstattede sparsommelighed som den foretrukne forespørgselsmetode for Cassandra, blev 2i-funktionalitet bevaret med syntaksen “Opret indeks”. Hvis du var kommet fra Hf, var dette en rigtig nem måde at lære loven om utilsigtede konsekvenser. Jo mere du tilføjer, jo mere påvirker du skriveydelsen. Men med Cassandra udløste dette det større problem med skriveforstærkning. Med henvisning til skrivestien ovenfor tilføjede sekundære indekser et nyt trin ind i stien. Når en mutation på en indekseret kolonne opstår, udløses en indekseringsoperation, der indekserer data igen i en separat indeksfil. Flere indekser på et bord kan dramatisk øge diskaktivitet i en enkelt række skrive operation. Når en knude tager en høj mængde mutationer, kan resultatet være mættet diskaktivitet, som kan gøre de enkelte noder ustabile, hvilket giver 2i den fortjente vejledning af “brug sparsomt.”Indeksstørrelsen er ret lineær i denne implementering, men med re-indeksering kan mængden af diskplads, der kræves, være svært at planlægge i en aktiv klynge.
opbevaring vedhæftet sekundær indeksering (SASI) — SASI blev oprindeligt designet af et lille team hos Apple til at løse et specifikt forespørgselsproblem og ikke det generelle problem med sekundære indekser. For at være retfærdig over for det hold kom det væk fra dem i en brugssag, som det aldrig var designet til at løse. Velkommen til open source alle. De to forespørgselstyper, som SASI var designet til at adressere:
- finde rækker baseret på delvis datamatchning. Jokertegn eller lignende forespørgsler.
- Range forespørgsler på sparsomme data, specifikt tidsstempler. Hvor mange poster passer i et tidsinterval type forespørgsler.
det gjorde begge disse operationer ganske godt, og det behandlede også spørgsmålet om skriveforstærkning med legacy 2i. da mutationer præsenteres for en Cassandra-knude, indekseres dataene i hukommelsen under den indledende skrivning, ligesom hvordan memtables bruges. Der kræves ingen diskaktivitet på en permutation. En enorm forbedring på klynger med en masse skrive aktivitet. Når memtables skylles til sstables, skylles det tilsvarende indeks for dataene. Hver indeksfil skrevet er uforanderlig og knyttet til sstable, deraf navnet opbevaring vedhæftet. Når komprimering sker, genindekses data og skrives til en ny fil, når der oprettes nye sstables. Fra et diskaktivitetsperspektiv var dette en stor forbedring. Ulempen ved SASI var primært i størrelsen af de oprettede indekser. Indeksformatet på disken forårsagede en enorm mængde diskplads, der blev brugt til hver indekserede kolonne. Dette gør dem meget vanskelige at styre for operatører. Derudover blev SASI markeret som eksperimentel, og der er ikke sket meget med hensyn til funktionsforbedring. Mange fejl er blevet fundet over tid med dyre rettelser, der har bragt på diskussionen om, hvorvidt SASI bør fjernes helt. Hvis du har brug for det dybeste dyk på denne funktion, duy Hai Doan gjorde et fantastisk stykke arbejde med at nedbryde, hvordan SASI fungerer.
Hvad gør SAI bedre
det første, bedste svar på dette spørgsmål er, at SAI er evolutionær i naturen. Ingeniører indså, at kernearkitekturen for sekundær indeksering skulle løses fra bunden, men med solide lektioner, der er lært af tidligere implementeringer. Adressering af problemerne med skriveforstærkning og indeksfilstørrelse, mens du opretter en sti til bedre forespørgselsforbedringer i Cassandra, har været den primære mission. Hvordan behandler SAI begge disse emner?
Skriveforstærkning — som vi lærte af SASI, var indeksering i hukommelsen og skylning af indekser med SSTables den rigtige måde at holde sig på linje med, hvordan Cassandra-skrivestien fungerer, mens du tilføjer ny funktionalitet. Med SAI, når mutationen er anerkendt, hvilket betyder fuldt engageret, indekseres dataene. Med optimeringer og en masse test er indvirkningen på skriveydelsen meget forbedret. Du bør se bedre end en 40% stigning i gennemstrømning og over 200% bedre skrive latenser over 2i. når det er sagt, skal du stadig planlægge en stigning på 2 gange latenstid og gennemstrømning på indekserede tabeller sammenlignet med ikke-indekserede tabeller. For at citere Duy Hai Doan, “der er ingen magi,” bare god teknik.
Indeksstørrelse — dette er den mest dramatiske forbedring og uden tvivl, hvor det meste arbejde er udført. Hvis du følger en verden af databaseinternaler, ved du, at datalagring stadig er et livligt felt fyldt med løbende forbedringer. SAI bruger to forskellige typer indekseringsordninger baseret på datatypen.
- tekst – Inverterede indekser oprettes med udtryk opdelt i en ordbog. Den største forbedring er fra brugen af Trie – baseret indeksering, som giver meget bedre kompression, hvilket betyder mindre indeksstørrelser.
- numerisk – udnytte en datastruktur kaldet blok kd-træer, taget fra Lucene, som tilbyder fremragende rækkevidde forespørgsel ydeevne. En separat række-ID-liste opretholdes for at optimere for tokenordreforespørgsler.
med en stærk vægt på indekslagring var resultatet en massiv forbedring af lydstyrken i forhold til antallet af tabelindekser. Som du kan se i grafen nedenfor, blev den hurtige indeksering bragt af SASI hurtigt formørket af eksplosionen af diskbrug. Det gør ikke kun operationel planlægning en smerte, men indeksfilerne måtte læses under komprimeringshændelser, som kunne mætte diske, der fører til problemer med node-ydeevne.
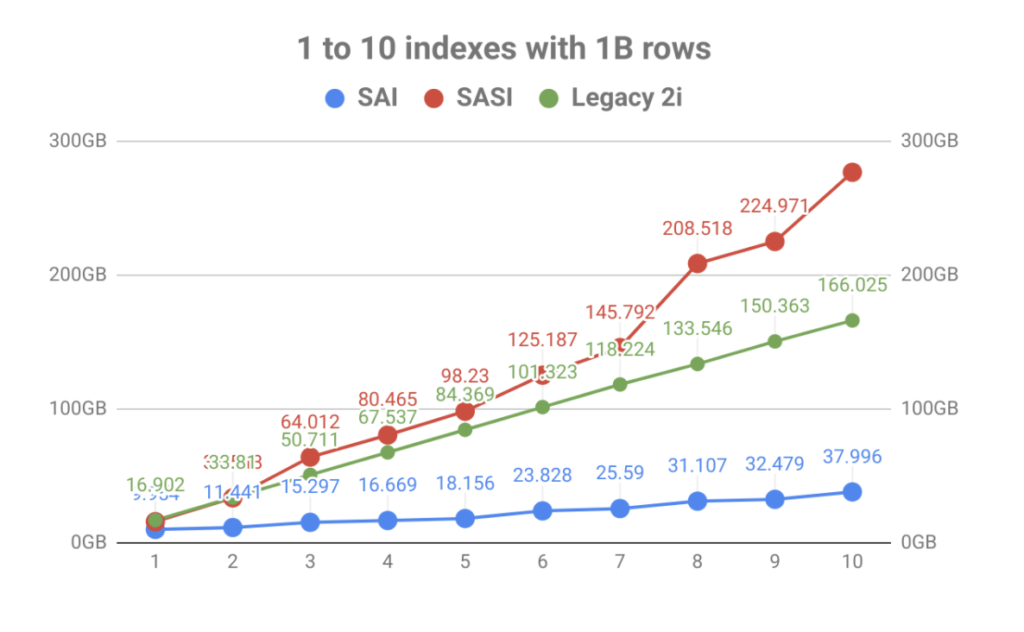
uden for skriveforstærkning og indeksstørrelse giver SAI ‘ s interne arkitektur mulighed for yderligere udvidelse og tilføjet funktionalitet i fremtiden. Dette er i tråd med projektmålene om at være mere modulære i fremtidige bygninger. Se på nogle af de andre CEPs, der afventer, og du kan se, at dette kun er begyndelsen.
Hvor går SAI herfra?
hvis du vil prøve dette nu, før det er en del af Apache Cassandra-projektet, har vi et par steder, du kan gå. For operatører eller folk, der kan lide lidt mere teknisk hands-on, kan du hente den nyeste Dataskat Enterprise 6.8. Hvis du er udvikler, er SAI nu aktiveret i Astra, vores Cassandra som en Service. Du kan oprette en gratis-evigt tier at lege med syntaks og nye hvor klausul funktionalitet. Lær med det, hvordan du bruger denne funktion ved at gå til siden Cassandra Indekseringsfærdigheder og inkluderet dokumentation.