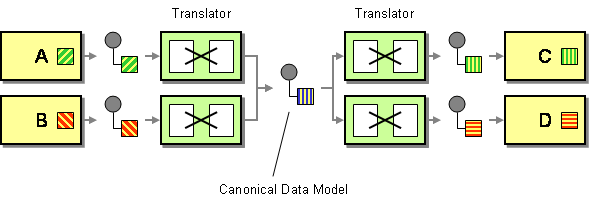
kanonický datový model je definován ve vzorcích podnikové integrace jako řešení pro minimalizaci závislostí při integraci aplikací, které používají různé formáty dat. Jinými slovy, komponenta (aplikace nebo služba) by měla komunikovat s jinou komponentou prostřednictvím datového formátu, který by byl nezávislý na obou datových formátech komponent.
zde je třeba zdůraznit dvě věci. Nejprve jsem definoval komponentu jako aplikaci nebo službu, protože takové modely jsou / byly použity v kontextu integrace aplikací a orientace na služby. Zadruhé zde hovoříme o konceptu,který by měl být použit pouze jako formát přepravních dat. Jako vnitřní strukturu úložiště dat byste neměli používat kanonický formát dat.
teoreticky jsou výhody zcela zřejmé. Formát kanonických dat snižuje vazbu mezi aplikacemi, snižuje počet překladů, které mají být vyvinuty pro integraci sady komponent atd. Docela zajímavé, že? Jeden jediný datový model je srozumitelný pro celé IT prostředí a soubor lidí (vývojáři ,systémoví analytici, obchodní zúčastněné strany atd.), kteří mohou sdílet stejnou vizi daného konceptu.
pro praktické účely je však implementace takových modelů zřídka účinná.
osoba není stejný koncept pro oddělení marketingu a podpory v pojišťovně. Let pro systém řízení letového provozu má jiný význam v závislosti na tom, zda byl vyplněn pilotem nebo zda se jedná o probíhající let nad Vaším vzdušným prostorem. Část PLM má zcela odlišné zastoupení v závislosti na tom, zda byla právě navržena nebo zda musí být udržována týmem podpory.
ve většině kontextů má návrh kanonického datového modelu za následek velký datový model s úplnou sadou volitelných atributů a velmi málo povinných (jako jsou identifikátory). I když byl primárně navržen tak, aby usnadnil integraci komponent, jen to zkomplikujete. Mezitím váš model vytvoří mezi uživateli spoustu frustrace kvůli své vlastní složitosti(z hlediska využití a správy). Kromě toho, pokud jde o problém se spojením, právě ji přesouváte někam jinam. Místo toho, abyste byli spojeni s jedním složkovým datovým formátem, stanete se pevně spojeni s jedním společným datovým formátem, který bude používán celým IT prostředím a podléhá velmi častým změnám.
Stručně řečeno, ve většině kontextů by měl být kanonický datový model považován za anti-vzor. Jaká je jiná možnost, než zvážit, měli byste stále chtít minimalizovat závislosti mezi dvěma složkami, které si vyměňují data?
Domain Driven Design (DDD) doporučuje zavést koncept ohraničeného kontextu. Ohraničený kontext je jednoduše explicitní kontext, ve kterém model platí s jasnými hranicemi s jinými ohraničenými kontexty. V závislosti na vaší organizaci by ohraničený kontext mohl odkazovat na funkční doménu, ve které je objekt využíván, mohl by odkazovat na samotný stav objektu atd.
v takovém případě by kanonický datový model jako takový byl jednoduše žlutou částí v následujícím diagramu:
průsečík a, B A C představuje sadu atributů, které tam musí být bez ohledu na kontext (v podstatě povinné atributy předchozího velkého CDM). Tato část by měla být stále pečlivě navržena kvůli své ústřední roli. Přesto je důležité zůstat pragmatický. Pokud ve vašem kontextu nemá smysl mít takový společný model, měli byste ho jednoduše zlikvidovat.
co je také důležité, je průnik mezi dvěma kontexty (A A B, B A C, C A A). Jak zmapovat reprezentaci jednoho objektu z jednoho kontextu do druhého? Jaké jsou explicitní atributy, které by měly být sdíleny ve dvou kontextech? Jaká jsou společná obchodní omezení mezi dvěma kontexty? Na tyto otázky by měl stále odpovídat příčný tým, ale z obchodního hlediska má smysl je vznášet. To nebylo vždy případ jednoho jediného CDM sdíleného v potenciálně opačných kontextech.
Nicméně pokud jde o části, které nejsou sdíleny s jinými kontexty (v bílé barvě), neměly by být součástí podnikového datového modelu. Měli byste být pragmatičtí. Pokud je například podmnožina specifická pro danou doménu, mělo by být na odbornících domény, aby ji sami modelovali.
jednou z klíčových výzev je však identifikovat tyto ohraničené kontexty a možná by stálo za to připomenout zde Conwayův zákon:
každá organizace, která navrhuje systém, nevyhnutelně vytvoří návrh, jehož struktura je kopií komunikační struktury organizace.
ohraničené kontexty nemusí být nutně mapovány na aktuální organizaci. Například ohraničený kontext může zahrnovat několik oddělení. Rozbití organizačních sil by mělo být pro většinu společností stále cílem.
kromě toho DDD zavádí koncept protikorupční vrstvy (ACL). Tento vzor může odkazovat na řešení pro starší migraci (zavedením mezivrstvy mezi starým a novým systémem, aby se zabránilo problémům s kvalitou dat atd.). Ale v našem kontextu, když mluvíme o korupci, souvisí to s datovým modelováním dluhu, který můžete zavést k řešení krátkodobých problémů.
Vezměme si příklad dvou systémů odpovědných za řízení daného stavu části PLM (část je fyzická položka vyrobená nebo zakoupená a poté sestavená jako například rotor vrtulníku). Jeden starší systém (nazvěme to SystemA) má na starosti správu fáze návrhu a musíte implementovat nový systém (nazvěme to SystemZ), který má na starosti správu fáze údržby. Celé prostředí aplikace IT sdílí stejný identifikátor společné části (partId) s výjimkou Systemy, která si toho není vědoma. Místo partId, SystemA spravuje svůj vlastní identifikátor, systemAId. Vzhledem k tomu, SystemZ musí být volání SystemA pomocí systemAId, heuristické by mohlo být integrovat systemAId jako součást datového modelu SystemZ.
Toto je běžná chyba, které byste se měli vyhnout. Jednoduše jste poškodili svůj datový model kvůli krátkodobé situaci.
vzor ACL zde mohl být řešením. SystemZ mohl implementovat svůj vlastní datový formát (bez vnější korupce, jako je systemAId). Pak by bylo na zprostředkující vrstvě, která by spravovala překlad mezi partId a systemAId.
aplikováno na naše téma, vzor ACL vynucuje implementaci vrstvy mezi dvěma různými ohraničenými kontexty. Komponenta si není vědoma toho, jak volat jinou komponentu, která není součástí jejího vlastního ohraničeného kontextu. Místo toho si komponenta uvědomuje pouze to, jak zmapovat svou vlastní datovou strukturu na datovém formátu ohraničeného kontextu, do kterého patří.
mimochodem, toto je pravidlo. Součást musí patřit pouze do jednoho ohraničeného kontextu. To je také důvod, proč se DDD skvěle hodí pro architekturu microservices. Vzhledem k jemnozrnné zrnitosti je snazší dodržovat toto pravidlo.
abychom to shrnuli, kanonický model jako takový by měl být ve většině případů považován za anti-vzor. Měli byste se pokusit implementovat koncept ohraničeného kontextu, což znamená Jeden model na kontext s explicitními hranicemi mezi kontexty. Dvě složky, které jsou součástí různých ohraničených kontextů, by měly komunikovat prostřednictvím protikorupční vrstvy, aby se zabránilo korupci při modelování dat.