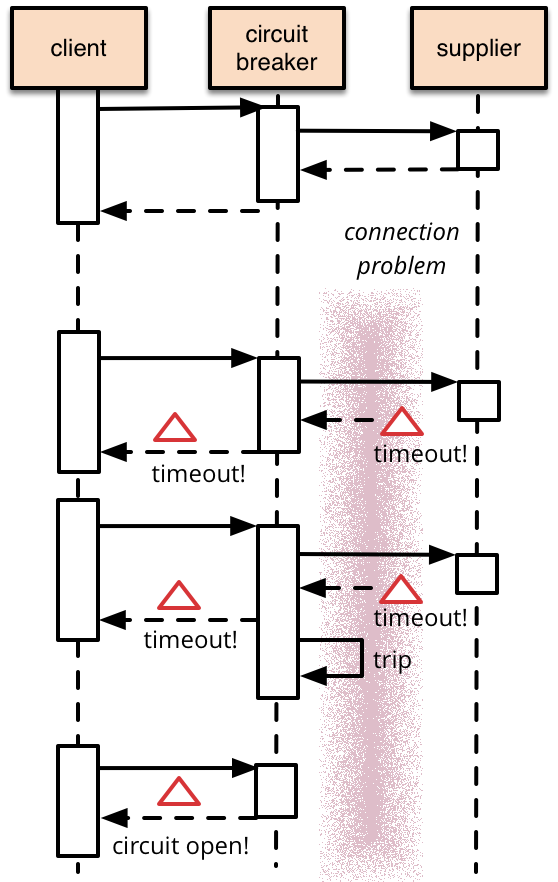
je běžné, že softwarové systémy provádějí vzdálená volání k softwaru běžícímu v různých procesech, pravděpodobně na různých počítačích v síti. Jedním z velkých rozdílů mezi hovory v paměti a vzdálenými hovory je to, že vzdálené hovory mohou selhat nebo viset bez odpovědi, dokud není dosaženo určitého časového limitu. Co je horší, pokud máte mnoho volajících na nereagujícího dodavatele, pak můžete vyčerpat kritické zdroje vedoucí k kaskádovým selháním ve více systémech. Ve své vynikající knize Release It Michael Nygard popularizoval vzor jističe, aby zabránil tomuto druhu katastrofické kaskády.
základní myšlenka jističe je velmi jednoduchá. Zabalíte volání Chráněné funkce do objektu jističe, který monitoruje poruchy. Jakmile poruchy dosáhnou určité prahové hodnoty, jistič se vypne a všechna další volání na jistič se vrátí s chybou, aniž by se Chráněné volání vůbec uskutečnilo. Obvykle budete také chtít nějaký druh upozornění na monitor, pokud se jistič vypne.
zde je jednoduchý příklad tohoto chování v Ruby, ochrana proti časovým limitům.
nastavil jsem jistič blokem (Lambda), který je chráněným voláním.
cb = CircuitBreaker.new {|arg| @supplier.func arg}
jistič ukládá blok, inicializuje různé parametry (pro prahové hodnoty, časové limity a monitorování) a resetuje jistič do uzavřeného stavu.
třída CircuitBreaker…
attr_accessor :invocation_timeout, :failure_threshold, :monitor def initialize &block @circuit = block @invocation_timeout = 0.01 @failure_threshold = 5 @monitor = acquire_monitor reset end
volání jističe vyvolá základní blok, pokud je obvod uzavřen, ale vrátí chybu, pokud je otevřený
# client code aCircuitBreaker.call(5)
třída CircuitBreaker…
def call args case state when :closed begin do_call args rescue Timeout::Error record_failure raise $! end when :open then raise CircuitBreaker::Open else raise "Unreachable Code" end end def do_call args result = Timeout::timeout(@invocation_timeout) do @circuit.call args end reset return result end
pokud dostaneme časový limit, zvýšíme počítadlo selhání, úspěšné volání jej resetuje zpět na nulu.
třída CircuitBreaker…
def record_failure @failure_count += 1 @monitor.alert(:open_circuit) if :open == state end def reset @failure_count = 0 @monitor.alert :reset_circuit end
určuji stav jističe porovnáním počtu poruch s prahovou hodnotou
třída CircuitBreaker…
def state (@failure_count >= @failure_threshold) ? :open : :closed end
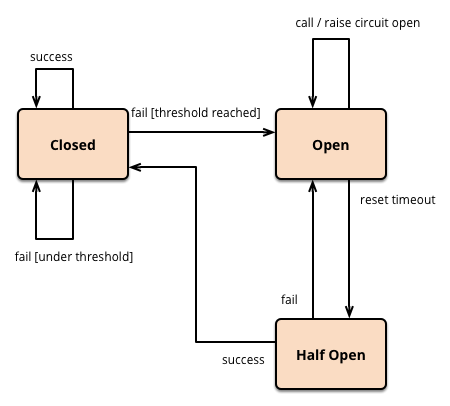
tento jednoduchý jistič zabraňuje tomu, aby se Chráněné volání stalo, když je obvod otevřený,ale potřeboval by externí zásah, aby se resetoval, když je vše v pořádku. To je rozumný přístup s elektrickými jističi v budovách, ale pro softwarové jističe můžeme nechat jistič sám zjistit, zda základní volání znovu fungují. Toto chování s vlastním resetováním můžeme implementovat opětovným pokusem o chráněné volání po vhodném intervalu a resetováním jističe, pokud uspěje.
vytvoření tohoto druhu jističe znamená přidání prahové hodnoty pro vyzkoušení resetování a nastavení proměnné, která drží čas poslední chyby.
třída ResetCircuitBreaker…
def initialize &block @circuit = block @invocation_timeout = 0.01 @failure_threshold = 5 @monitor = BreakerMonitor.new @reset_timeout = 0.1 reset end def reset @failure_count = 0 @last_failure_time = nil @monitor.alert :reset_circuit end
nyní je přítomen třetí stav-napůl otevřený – což znamená, že obvod je připraven provést skutečné volání jako pokus, aby zjistil, zda je problém vyřešen.
třída ResetCircuitBreaker…
def state case when (@failure_count >= @failure_threshold) && (Time.now - @last_failure_time) > @reset_timeout :half_open when (@failure_count >= @failure_threshold) :open else :closed end end
požádán o volání v polootevřeném stavu má za následek zkušební volání, které buď resetuje jistič, pokud bude úspěšný, nebo restartuje časový limit, pokud ne.
třída ResetCircuitBreaker…
def call args case state when :closed, :half_open begin do_call args rescue Timeout::Error record_failure raise $! end when :open raise CircuitBreaker::Open else raise "Unreachable" end end def record_failure @failure_count += 1 @last_failure_time = Time.now @monitor.alert(:open_circuit) if :open == state end
tento příklad je jednoduchý vysvětlující, v praxi jističe poskytují dobrý trochu více funkcí a parametrizaci. Často budou chránit před řadou chyb, které by chráněné volání mohlo vyvolat, jako jsou selhání síťového připojení. Ne všechny chyby by měly vypínat obvod, některé by měly odrážet normální poruchy a být řešeny jako součást běžné logiky.
se spoustou provozu můžete mít problémy s mnoha hovory, které čekají na počáteční časový limit. Vzhledem k tomu, vzdálené hovory jsou často pomalé, je to často dobrý nápad, aby každý hovor na jiném vlákně pomocí budoucnost nebo slib zvládnout výsledky, když se vrátí. Nakreslením těchto vláken z fondu vláken můžete zajistit, aby se obvod zlomil, když je fond vláken vyčerpán.
příklad ukazuje jednoduchý způsob vypnutí jističe-počet, který se resetuje při úspěšném volání. Sofistikovanější přístup by se mohl podívat na frekvenci chyb, zakopnutí, jakmile získáte, řekněme, 50% poruchovost. Můžete mít také různé prahové hodnoty pro různé chyby, například prahová hodnota 10 pro časové limity, ale 3 pro selhání připojení.
příklad, který jsem ukázal, je jistič pro synchronní volání, ale jističe jsou také užitečné pro asynchronní komunikaci. Běžnou technikou je umístit všechny požadavky do fronty , kterou dodavatel spotřebuje svou rychlostí-užitečná technika, aby se zabránilo přetížení serverů. V tomto případě se obvod přeruší, když se fronta zaplní.
samy o sobě jističe pomáhají snižovat zdroje spojené s operacemi, které pravděpodobně selžou. Vyhnete se čekání na časové limity pro klienta a přerušený obvod zabrání zatížení bojujícího serveru. Mluvím zde o vzdálených hovorech, které jsou běžným případem jističů, ale lze je použít v jakékoli situaci, kdy chcete chránit části systému před poruchami v jiných částech.
jističe jsou cenným místem pro monitorování. Jakákoli změna stavu jističe by měla být zaznamenána a jističe by měly odhalit podrobnosti o jejich stavu pro hlubší sledování. Chování jističe je často dobrým zdrojem varování o hlubších problémech v životním prostředí. Operační personál by měl být schopen vypínat nebo resetovat jističe.
jističe samy o sobě jsou cenné, ale klienti, kteří je používají, musí reagovat na selhání jističe. Stejně jako u jiných vzdálených vyvolání je třeba zvážit, co dělat v případě selhání. Selhává operace, kterou provádíte, nebo existují řešení, která můžete udělat? Autorizace kreditní karty by mohla být zařazena do fronty k řešení později, neschopnost získat některá data může být zmírněna zobrazením některých zastaralých dat, která jsou dostatečně dobrá na zobrazení.
další čtení
Netflix tech blog obsahuje mnoho užitečných informací o zlepšení spolehlivosti systémů se spoustou služeb. Jejich příkaz závislostí hovoří o použití jističů a limitu fondu vláken.
Netflix má otevřený zdroj Hystrix, sofistikovaný nástroj pro řešení latence a odolnosti proti chybám pro distribuované systémy. Zahrnuje implementaci vzoru jističe s limitem fondu závitů
existují další open-source implementace vzoru jističe v Ruby, Java, Grails Plugin, C#, AspectJ a Scala
poděkování
Pavel Špák si všiml a nahlásil chybu v ukázkovém kódu