nedávno došlo k novému návrhu změny pro indexování Cassandra, který se pokouší snížit kompromis mezi použitelností a stabilitou: čímž je klauzule WHERE mnohem zajímavější a užitečnější pro koncové uživatele. Tato nová metoda se nazývá indexování připojené k úložišti (SAI). Není to nejchytřejší jméno, ale co čekáš? Inženýři nejsou známí pro pojmenování věcí, ale skvělá technologie není nikdy vtip. SAI upoutal pozornost komunity Cassandra, ale proč? Indexování dat není ve světě databází novým konceptem.
jak indexujeme naše data, se mohou v průběhu času měnit na základě požadovaných případů použití a modelů nasazení. Cassandra byla postavena kombinací aspektů Dynamo a Big Table, aby se snížila složitost čtení a zápisu režie tím, že se věci udržují jednoduché. Složitost Cassandry byla většinou vyhrazena její distribuované povaze a v důsledku toho vytvořila kompromis pro vývojáře. Pokud chcete neuvěřitelnou škálu Cassandry, musíte trávit čas učením se, jak datový model. Databázové indexy jsou určeny k vylepšení datového modelu a zefektivnění vašich dotazů. Pro Cassandru existují v nějaké formě od prvních dnů projektu. Nešťastnou skutečností je, že se dobře neshodovaly s požadavky uživatelů. Jakékoli použití indexování přichází s dlouhým seznamem kompromisů a varování do té míry, že se jim většinou vyhýbají a pro některé, jen těžké ne. V důsledku toho se uživatelé naučili, jak modelovat data se základními dotazy, aby získali nejlepší výkon.
tyto dny mohou být za námi a funkce jako SAI nám pomáhají se tam dostat.
sekundární indexy v distribuovaných databázích
ne všechny indexy jsou vytvořeny stejné. Primární indexy jsou také známé jako jedinečný klíč, nebo v Cassandra slovníku, partition key. Jako metoda primárního přístupu k databázi využívá Cassandra klíč oddílu k identifikaci uzlu, který drží data, a pak datový soubor, který ukládá oddíl dat. Primární index čte v Cassandra jsou poměrně jednoduché, ale nad rámec tohoto článku. Více o nich si můžete přečíst zde.
sekundární indexy vytvářejí zcela odlišnou a jedinečnou výzvu v distribuované databázi. Podívejme se na příklad tabulky, abychom vytvořili několik bodů:
vytvořit uživatele tabulky (
ID long,
firstName text,
lastName text,
country text,
created timestamp,
PRIMARY KEY (id)
);
primární vyhledávání indexu by bylo docela jednoduché:
vyberte křestní jméno, příjmení od uživatelů, kde id = 100;
Co kdybych chtěl najít všechny ve Francii? Jako někdo obeznámený s SQL, očekávali byste, že tento dotaz bude fungovat:
vyberte křestní jméno, příjmení od uživatelů, kde country = ‚FR‘;
bez vytvoření sekundárního indexu v Cassandře se tento dotaz nezdaří. Základní přístupový vzor v Cassandře je pomocí partition key. V nedistribuované databázi, jako je tradiční RDBMS, je každý sloupec tabulky snadno viditelný pro systém. Stále máte přístup ke sloupci, i když neexistuje žádný index, protože všechny existují ve stejném systému a datových souborech. Indexy v tomto případě pomáhají zkrátit dobu dotazu tím, že vyhledávání zefektivní.
v distribuovaném systému, jako je Cassandra, jsou hodnoty sloupců v každém datovém uzlu a musí být zahrnuty do plánu dotazů. Tím se nastaví to, čemu říkáme scénář „Scatter-Gather“, kdy je dotaz odeslán do každého uzlu, data jsou shromažďována, sloučena a vrácena uživateli. I když lze tuto operaci provést na více uzlech najednou, správa latence závisí na tom, jak rychle může uzel najít hodnotu sloupce.
Rychlá recenze Cassandra data writes
možná si myslíte, že přidávání indexů je o čtení dat, což je určitě konečný cíl. Při vytváření databáze jsou však technické výzvy týkající se indexování zkreslené v místě, kde jsou data zapsána. Přijetí dat nejrychlejší rychlostí při formátování indexů v nejoptimálnější formě pro čtení je obrovská výzva. Stojí za to udělat rychlý přehled o tom, jak jsou data zapsána v databázi Cassanda na úrovni jednotlivých uzlů. Podívejte se na následující diagram, jak vysvětluji, jak to funguje.
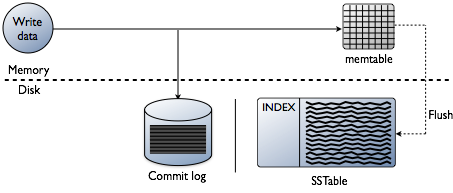
když jsou data prezentována uzlu, kterému říkáme mutace, cesta zápisu pro Cassandru je velmi jednoduchá a optimalizovaná pro tuto operaci. To platí také pro mnoho dalších databází založených na stromech LSM(Log-Structured Merge).
- Ověření dat je správný formát. Zadejte kontrolu proti schématu.
- zapisuje data do ocasu protokolu odevzdání. Ne hledá, jen další místo na ukazateli souboru.
- zapisovat data do memtable, což je jen hashmap schématu v paměti.
Hotovo! Mutace je uznána, když se tyto věci stanou. Miluji, jak jednoduché je to ve srovnání s jinými databázemi, které vyžadují zámek a snaží se provést zápis.
později, když memtables vyplní fyzickou paměť, proces flush zapíše segmenty V jednom průchodu na disk do souboru zvaného SSTable (tabulka seřazených řetězců). Doprovodný protokol odevzdání je nyní smazán, když se persistence přesunula do SSTable. Tento proces se opakuje, protože data jsou zapsána do uzlu.
důležitý detail: SSTables jsou neměnné. Jakmile jsou napsány, nikdy se neaktualizují, jen vymění. Nakonec, jak je zapsáno více dat, proces na pozadí zvaný zhutnění sloučí a třídí sstables do nových, které jsou také neměnné. Existuje mnoho zhutňovacích schémat,ale v zásadě všichni tuto funkci vykonávají.
Nyní máte dostatek základního základu na Cassandře, abychom se mohli dostat dostatečně nerdy s indexy. Jakákoli další hloubka informací je ponechána jako cvičení pro čtenáře.
problémy s předchozím indexováním
Cassandra měla dvě předchozí implementace sekundárního indexování. Sekundární indexování(Sasi) a sekundární indexy připojené k úložišti, které označujeme jako 2i. Opět platí, že můj názor na inženýry, kteří nejsou okázalí jmény, zde drží. Sekundární indexy byly součástí Cassandry od začátku, ale implementace je znepříjemnily koncovým uživatelům s jejich dlouhým seznamem kompromisů. Dvě hlavní obavy, které jsme jako projekt neustále řešili, jsou zesílení zápisu a velikost indexu na disku. Jako výsledek, mohou být frustrovaně lákavé pro nové uživatele, jen aby je později při nasazení selhali. Podívejme se na každého.
sekundární indexy (2i) – tato původní práce v projektu začala jako funkce pohodlí pro rané Spořivé datové modely. Později, když Cassandra Query Language nahradil Thrift jako preferovanou metodu dotazu pro Cassandru, funkce 2i byla zachována se syntaxí“ vytvořit INDEX“. Pokud jste přišli z SQL, byl to opravdu snadný způsob, jak se naučit zákon nezamýšlených důsledků. Stejně jako v SQL indexování, čím více přidáte, tím více ovlivníte výkon zápisu. U Cassandry to však vyvolalo větší problém se zesílením zápisu. S odkazem na výše uvedenou cestu zápisu přidaly sekundární indexy do cesty nový krok. Když dojde k mutaci na indexovaném sloupci, spustí se operace indexování, která znovu indexuje data v samostatném indexovém souboru. Více indexů v tabulce může dramaticky zvýšit aktivitu disku v jedné řádkové operaci zápisu. Když uzel bere velké množství mutací, výsledkem může být nasycená aktivita disku, která může způsobit nestabilitu jednotlivých uzlů, dávat 2i zasloužené vedení „používat střídmě.“Velikost indexu je v této implementaci poměrně lineární, ale s opětovným indexováním může být obtížné naplánovat potřebné místo na disku v aktivním clusteru.
storage Attached Secondary Indexing (SASI) – SASI byl původně navržen malým týmem společnosti Apple, aby vyřešil konkrétní problém dotazu a ne obecný problém sekundárních indexů. Abych byl spravedlivý k tomuto týmu, dostal se od nich v případě použití, který nebyl nikdy navržen k řešení. Vítejte v open source všem. Dva typy dotazů, které SASI byl navržen tak, aby řešit:
- hledání řádků na základě částečné shody dat. Zástupný znak, nebo jako dotazy.
- rozsah dotazů na řídká data, konkrétně časová razítka. Kolik záznamů se vejde do dotazů typu časového rozsahu.
obě tyto operace provedl docela dobře a také se zabýval otázkou zesílení zápisu pomocí legacy 2i. vzhledem k tomu, že mutace jsou prezentovány uzlu Cassandra, jsou data indexována v paměti během počátečního zápisu, podobně jako použití memtables. Při permutaci není nutná žádná aktivita disku. Obrovské zlepšení klastrů s velkou aktivitou zápisu. Když jsou memtables propláchnuty na sstables, odpovídající index pro data je propláchnut. Každý zapsaný indexový soubor je neměnný a připojený k sstable, proto je připojeno úložiště názvů. Dojde-li ke zhutnění, data jsou reindexovány a zapsány do nového souboru jako nové sstables jsou vytvořeny. Z hlediska činnosti disku to bylo zásadní zlepšení. Nevýhodou SASI byla především velikost vytvořených indexů. Formát indexu na disku způsobil obrovské množství místa na disku použitého pro každý indexovaný sloupec. To je pro operátory velmi obtížné zvládnout. Kromě toho byl SASI označen jako experimentální a s ohledem na zlepšení funkcí se toho moc nestalo. V průběhu času bylo nalezeno mnoho chyb s drahými opravami, které vedly k diskusi o tom, zda by SASI měla být zcela odstraněna. Pokud potřebujete nejhlubší ponor na tuto funkci, Duy Hai Doan odvedl úžasnou práci, když rozebral, jak Sasi funguje.
co dělá SAI lepší
první, nejlepší odpověď na tuto otázku je, že SAI je evoluční povahy. Inženýři v Datastaxu si uvědomili, že základní architekturu sekundárního indexování je třeba řešit od základu, ale se solidními lekcemi, které byly získány z předchozích implementací. Primárním posláním bylo řešení otázek zesílení zápisu a velikosti indexového souboru při vytváření cesty pro lepší vylepšení dotazů v Cassandře. Jak SAI řeší obě tato témata?
Write amplification-jak jsme se dozvěděli od SASI, indexování v paměti a proplachování indexy SSTables byl správný způsob, jak udržet v souladu s tím, jak Cassandra write-path funguje, při přidávání nových funkcí. S SAI, když je mutace uznána, což znamená, že je plně oddána, jsou data indexována. Díky optimalizacím a spoustě testování se dopad na výkon zápisu výrazně zlepšil. Měli byste vidět lépe než 40% zvýšení propustnosti a více než 200% lepší latence zápisu nad 2i. jak již bylo řečeno, měli byste stále plánovat zvýšení latence a propustnosti 2x na indexovaných tabulkách ve srovnání s neindexovanými tabulkami. Citovat Duy Hai Doan, „neexistuje žádná magie,“ jen dobré inženýrství.
Velikost indexu-to je nejdramatičtější zlepšení a pravděpodobně tam, kde byla většina práce vykonána. Pokud sledujete svět databázových vnitřků, víte, že ukládání dat je stále živé pole plné neustále se vyvíjejících vylepšení. SAI používá dva různé typy indexovacích schémat založených na datovém typu.
- textové indexy jsou vytvořeny s termíny rozdělenými do slovníku. Největší zlepšení je z použití trie založené indexování, které nabízí mnohem lepší kompresi, což znamená menší velikosti indexu.
- numerické-s využitím datové struktury zvané block KD-stromy, převzaté z Lucene, který nabízí vynikající rozsah výkonu dotazu. Pro optimalizaci dotazů na pořadí tokenů je udržován samostatný seznam ID řádků.
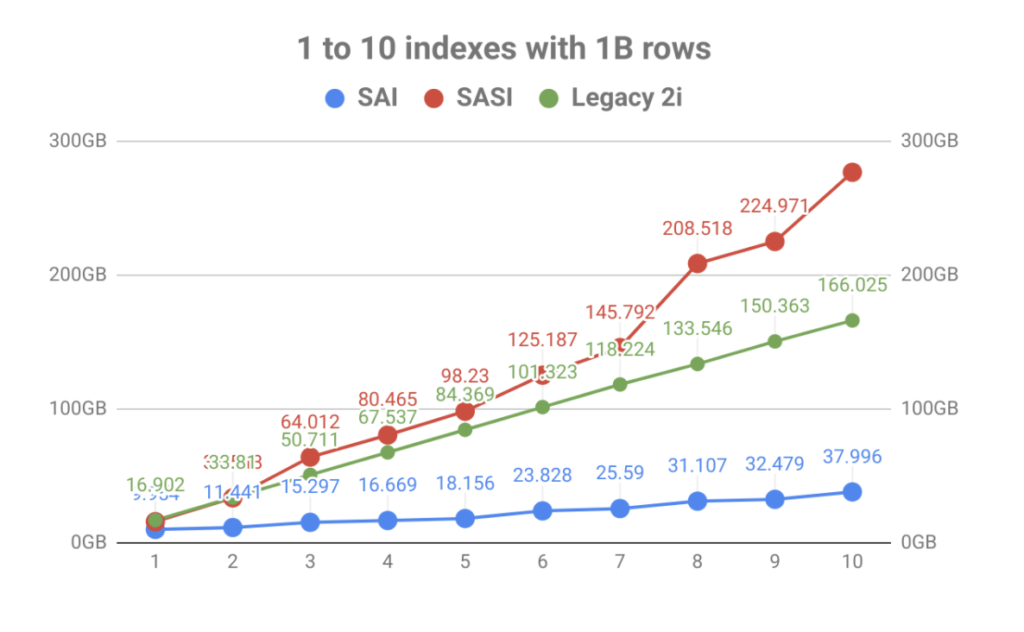
se silným důrazem na ukládání indexů bylo výsledkem masivní zlepšení objemu oproti počtu indexů tabulky. Jak můžete vidět v grafu níže, rychlé indexování přinesené SASI bylo rychle zastíněno explozí využití disku. Nejen, že to dělá operační plánování bolest, ale indexové soubory musely být čteny během zhutňování událostí, které by mohly nasytit disky vedoucí k problémům s výkonem uzlu.
mimo zesílení zápisu a velikost indexu, vnitřní architektura SAI umožňuje další rozšíření a další funkce v budoucnu. To je v souladu s cíli projektu, aby bylo v budoucích stavbách modulárnější. Podívejte se na některé z dalších CEPs, které čekají, a můžete vidět, že je to jen začátek.
kde SAI jít odtud?
DataStax nabídl SAI projektu Apache Cassandra prostřednictvím procesu vylepšení Cassandra jako CEP-7. Nyní se diskutuje o zařazení do 4.x větev Cassandry.
pokud si to chcete vyzkoušet nyní, než bude součástí projektu Apache Cassandra, máme pro vás pár míst. Pro operátory nebo lidi, kteří mají rádi trochu více technických praktik, si můžete stáhnout nejnovější DataStax Enterprise 6.8. Pokud jste vývojář, SAI je nyní povolen v DataStax Astra, naše Cassandra jako služba. Můžete si vytvořit vrstvu navždy zdarma, abyste si mohli pohrát se syntaxí a novou funkčností klauzule where. S tím, Naučte se používat tuto funkci tím, že přejdete na stránku indexování dovedností Cassandra a přiloženou dokumentaci.